1. 메모리
들어가기 전에
우리가 C로 작성한 변수들은 실제로 컴퓨터 메모리에 어떻게 저장될까요? 메모리 주소를 나타내는 방법과 그 주소를 알아내는 방법, 그 주소에 찾아가는 방법을 배워봅시다.
학습 목표
16진법을 읽고 쓸 수 있습니다.
메모리 주소에 접근하고 값을 받아오는 코드를 C로 작성할 수 있습니다.
핵심 단어
- 16진법
- 메모리 주소
학습하기

지난주까지는 알고리즘에 대해 집중적으로 배웠다. 비교와 교환을 수없이 했었다. 알고리즘과 개념적인 부분을 많이 다뤘다면, 오늘은 좀더 실용적이고 체계적인 부분에 집중할 것이다. 그렇다면 이 보조 바퀴를 우선 떼는 것이 좋을 것이다.
16진수
제일 먼저 배울 것은 수를 세는 방식이다. 첫 주에 배운 내용을 기억해보면, 이미 우리에게 익숙한 10진법을 배웠고, 2진법도 배웠다. 10과 2의 거듭제곱 외에도 다른 숫자를 진수로 사용하는 진법도 있었다. 이 사실이 중요한 이유는, 오늘 우리가 배우게 될 컴퓨터의 메모리와 파일, 즉 컴퓨터나 휴대폰에 있는 이미지와 같은 파일을 만들거나 수정할 때 컴퓨터나 휴대폰 속 메모리의 위치를 표현하는데 매우 유용하기 때문이다. 각 바이트에 고유한 숫자를 부여하여 메모리 속 내용물에 대해 이야기할 수 있다.

여기 보이는 것처럼 0, 1, 2, 3, ... 15와 같이 적을 수 있다. 일반적으로 쓰는 방법은 아니지만 문제될 건 없다. 이것을 지금부터는 조금 다르게 표현해보겠다.

0, 1, 2, 3, 4, 5, 6, 7, 8, 9까지 적고 10진법도 2진법도 아닌 16진법을 사용한다면, 9보다 큰 숫자를 어떻게 셀 수 있을까? 문자 A, B, C, D, E, F라고 쓸 수 있다. 왜일까? 알파벳을 사용하면 한자리로 0부터 9까지 뿐만 아니라 10, 11, 12, 13, 14, 15까지 셀 수 있게 된다. F는 15를 의미한다.
이 내용을 알려주는 이유는 이런 패턴이 앞으로 계속 나올텐데, 컴퓨터가 숫자를 10진수나 2진수가 아닌 16진수로 표현할 때가 많기 때문이다. 왜인지는 곧 보자.
2진법에는 0과 1이 있고, 10진법에는 0에서 9까지 있고, 16진수는 0부터 F까지 있다. F는 15이다. 실제로 이는 어떻게 동작할까?

빠르게 복습해보면 2진수는 이렇게 표현했었다. 0 bit가 8개(=1byte) 있고, 각 bit는 한 이진수를 의미한다. 숫자를 계산해서 적으면 아래와 같이 된다.

이 숫자를 10진수로 표현하면 무엇일까? 0이다. 각 자릿수를 위의 값과 곱하면 0이다.

이건? 모든 0을 1로 바꿔서 8비트로 표현할 수 있는 가장 큰 숫자가 뭐였을까?
255가 셀 수 있는 가장 큰 값이다. 256이라 생각할 수 있지만, 0부터 세기 때문에 0을 하나의 수로 사용하여, 255가 8비트로 셀 수 있는 가장 큰 값이 된다. 직접 계산해보면 128+64+...+1 = 255가 나온다.

10진법에서는 각 자릿수가 10의 거듭제곱을 의미한다. 예를 들어, 1, 10, 100이다.

255를 다른 방식으로 표현하기 위해 16진법을 사용할 수 있다. 2나 10의 거듭제곱이 아닌 16의 거듭제곱을 사용한다. 연산을 할 때 이렇게 표현하면 매우 편리하다고 한다.
맨 오른쪽 열은 16의 0승, 즉 1의 자리이고, 두 번째 열은 16의 자리이다( 16 0 ). 참고로 F는 15였기 때문에 비슷하게 셀 수 있다.

위의 수는 16진수로 0이다. 16 x 0 + 1 x 0 = 0이니까. 매우 간단하다.

이후 1, 2, 3, 4, 5, 6, 7, 8, 9까지는 10진법과 동일하다. 10진법에서 10을 표현하려면 "1 0" 으로 적지만, 16진법에서는 좀 더 셀 수 있다. A, B, C, D, E, F까지이다. F가 15가 된다. 왜일까? 16 x 0 + 1 x F = 15. 따라서 15이다.
그렇다면 16이상은 어떻게 셀까?

예상했겠지만, 10진법이나 2진법에서 했던 것처럼 1을 올려주면 16진법에서 "1 0" 은 "16"이 된다. 여기서 '십'이라고 읽으면 안된다. 그건 10진수 숫자이다. 이 숫자는 16진법의 '일 영'이다.
매우 기본적인 수준의 내용이다. 일반적으로 우리는 16진법으로 생각하지 않지만, 앞으로 16진법 숫자를 많이 볼 것이다. 그리고 이 숫자를 우리가 친숙한 10진법이나 진법의 수로 바꿀 수 있다.
"2 0"은 16 x 2 = 32고, 0을 더하니 32이다. 1이 네 개가 있고 또 네 개가 있다면( 0000 0000 ), FF로 표현할 수 있다. 사실 우리는 FF나 00과 같은 숫자를 본 적이 있을 것이다. HTML, CSS으로 웹 디자인을 해본 사람이라면 말이다.
우선 첫 주에 배운 RGB를 떠올려보자. 컴퓨터는 빨간색, 초록색, 파란색으로 색을 표현하는데 각 픽셀을 일정량의 빨,초,파로 나타낸다. 사실은 사람이 쉽게 표현하기 위해 16진법으로 각 색의 양을 나타내도록 정한 것이다.

여기선 빨, 초, 파가 없다는 것이다. 이것은 검은색이다. 어떤 색도 포함되어 있지 않다면 검은 색이다.

하지만 만약 FF가 있다면 이것은 뭘까? 255만큼의 빨간색이 있고 초, 파는 여전히 0이다. 컴퓨터 화면에 빨간색 픽셀이 보이다면 그 픽셀은 FF0000이라는 값을 가지고 있을 것이다. 빨간색이 많이 있고, 초록색과 파란색은 없다는 말이다.

이처럼 세 개의 색을 모두 섞으면 컴퓨터가 흰색을 나타내게 된다. 나중에 게임, 웹 혹은 모바일 개발을 하게 되면 이 표기가 흔한 표기법이라는 것을 알게 될 것이다.
10진수를 16진수로 바꾸기
JPG 이미지 파일은 항상 255 216 255 로 시작되고 이것은 10진수이다. 하지만 실제 컴퓨터 내에서는 10진수를 사용하지 않는다. 컴퓨터는 0과 1만을 이해할 수 있기 때문이다.
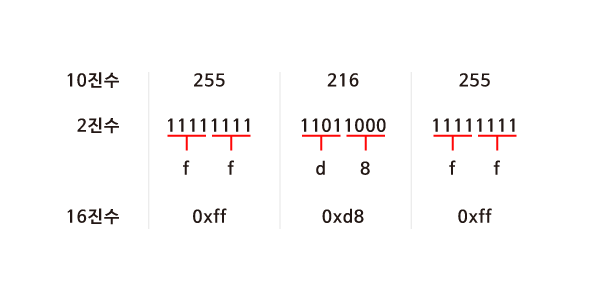
먼저 255 216 255를 2진수로 나타내보면 <그림 1>과 같다. 2진수로 모든 데이터를 표현하기에는 너무 길어지기 때문에 16진수로 바꾸어 보자. 2^4이 16이기 때문에 4bits씩 두 덩어리로 나누어 보면 0000 부터 1111까지는 16진수로 표현할 수 있다는 것을 알 수 있다.
16진수 표현법 (0x)

다시 돌아와 메모리의 생김새를 보면, 이는 격자로 구성된 바이트들이다. 맨 처음을 0이라 하고, 맨 마지막을 1F라 하고, 계속 늘려갈 수 있다. 하지만 처음보면 헷갈릴 수 있다. 이게 10진수인지 16진수인지, 아니면 완전 다른 진수인가?
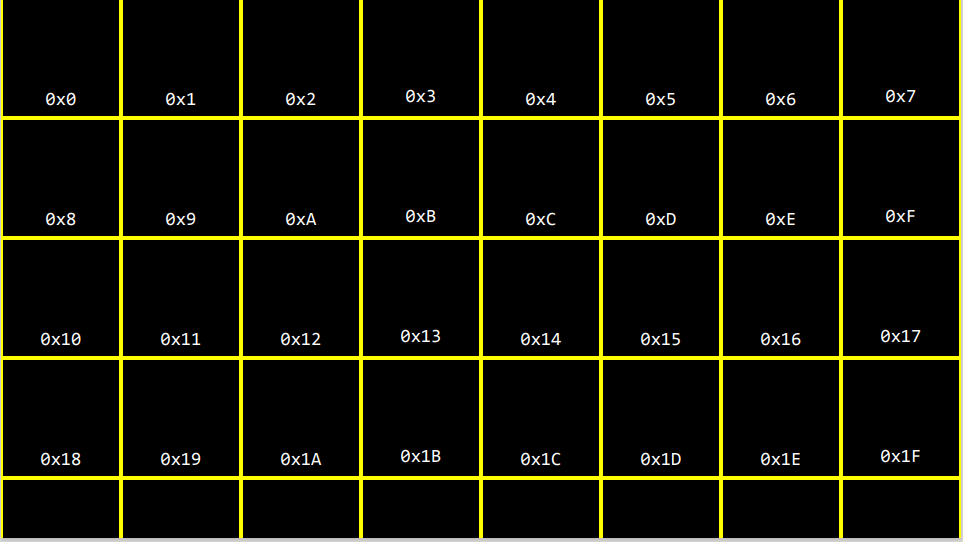
이런 모호함을 없애기 위해서 16진수를 사용할 때는 모든 수 앞에 0x를 붙이기로 약속했다. 0x는 수학적으로 아무런 의미가 없지만, 앞으로 나오는 값이 16진수라는 것을 알려준다. 이렇게하면 10진수와 헷갈리지 않게 된다.
16진수의 유용성
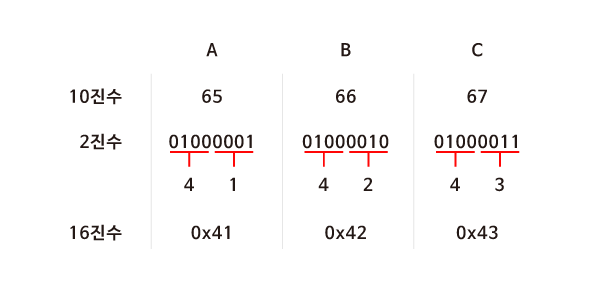
ASCII 코드에 의해 “A, B, C”는 10진수로 65, 66, 67에 해당한다. 컴퓨터는 10진수를 이해할 수 없으므로 2진수로 표현해보면 "01000001 01000010 01000011"이 돈다. 컴퓨터가 처리할 수 있어야 하기 때문에 어쩔 수 없지만 그 길이가 너무 긴 것을 알 수 있다.
하지만 16진수로 표현하면 2진수로 표현했을 때 보다 훨씬 간단해진다. 또한 컴퓨터는 8개의 비트가 모인 바이트 단위로 정보를 표현한다. 2개의 16진수는 1byte의 2진수로 변환되기 때문에 정보를 표현하기 매우 유용하다.
그렇다면 진수에 대한 것은 여기까지 배워보고, 이 정보를 어떻게 이용하는지 보자. 컴퓨터의 메모리 속에서 실제로 어떤 일이 벌어지는지 보고, 메모리를 다룰 때 왜 16진법이 적절한지, 그리고 메모리 세계에서 어떻게 메모리를 다루는지 보자.
int n = 50;여기 예시는 간단하게 n이라는 변수를 만들고, 그 변수에는 50이라는 값을 넣어둔다. 이제 이와 동일한 코드를 빠르게 만들어보자.
address.c라는 파일을 만들고, 컴퓨터 메모리의 주소를 다룰 것이라는 의미다. 처음에는 단순하게 가보자.
#include <stdio.h>
int main(void){
int n = 50;
printf("%i\n", n);
}위를 작성 후 make adress 입력하여 컴파일을 하고 ./address를 입력하면 50이 나온다. 그냥 변수에 50이 저장되어 있으니까. 여기까진 어렵지 않다.

이제 컴퓨터의 메모리 속에서 어떤 일이 벌어지는지 추론할 수 있다. 이게 컴퓨터의 메모리라고 생각해보자. 여기 어딘가에 우리가 저장한 변수 n이 있을 것이다.

4바이트의 크기로 여기 있다. int가 4바이트인 게 기억나는가? 그러니까 네 개의 네모를 차지한다. 일관성을 위해서 n이라 부르고 그 안에는 50이 있다. 더 깊게 내려가보면 50이 아니라, 32bits(=4byte)로 구성된 0과 1이 50을 표현하고 있을 것이다. 하지만 우리는 트랜지스터 같은 기초적인 수준의 내용은 다루지는 않을 것이다.
이 변수를 출력하려고 하면, 변수 n안에 있는 내용을 출력하는 것이다. 엄밀히 말해, 저 변수는 메모리 어딘가에 있다.
가장 왼쪽 위가 0이라 하고, 가장 오른쪽 아래에 큰 값이 있다고 할 때, 이 화면을 축소해서 이 변수 n과 그 안에 있는 값 50은 0x12345678이라는 위치에 있다고 가정해보자. 그게 어딘지는 중요하지 않다. 임의의 큰 수라고 하자. 메모리가 그 이상의 바이트를 가지는 한 메모리 어딘가에 존재한다는 말이다.
연산자 '&n'와 형식 지정자 '%p'
C언어를 사용하면, 이 위치 또한 확인할 수 있다. 코드를 조금 바꿔서 이번에는 n이 아니라 &n을 출력해보자. 이것은 C의 문법 중 하나로, "~의 주소"를 의미하는 연산자이다. n이 어디있던지 n의 주소를 알려준다. 메모리 속의 위치 말이다.
이를 위한 또 다른 형식 지정자가 있는데, 바로 %i 대신에 %p 를 쓸 수 있다. %p를 쓰면 주소를 출력해준다.
#include <stdio.h>
int main(void){
int n = 50;
printf("%p\n", &n);
}
CS50 IDE가 동작 중인 클라우드 서버에서 주소 0x12345678인 방금 설명을 위해 꾸며낸 위치가 아니라, 정확하게는 0x7fffeda4332c에 있다. 이 수업에서 큰 의미는 없지만 16진수란건 알 수 있다. 모든 자릿수가 0~F로 이루어져있다. 꽤 멋지지 않나요? 아직 크게 유용한 정보는 아니지만, 컴퓨터 메모리 속 어디에 값이 저장되어 있는 지 확인할 수 있다.
그 값은 뭘까? 그 값은 우리가 컴퓨터에 특정 값의 주소를 요구한 것으로, 여러분은 그 값을 가리키는 포인터 값을 돌려 받는다. 포인터는 컴퓨터 메모리의 주소를 가리키는 것이다. 그래서 %p라고 쓴다. printf에게 포인터 변수를, 즉 무언가의 주소를 출력해달라고 하는 것이다. 그리고 항상 16진수로 출력해준다.
연산자 '*n'
이것을 원래대로 만들 수도 있다. 하나만 해보겠다. 50을 다시 출력하고 싶다고 가정하자. 이 연산자의 효과를 뒤집을 수 있다. &n의 의미는 n의 주소를 달라는 것이다.
사실 C언어에는 반대 역할을 하는 연산자도 있다. &가 "~의 주소"를 의미하는 연산자였다면, * 또는 별표는 곱셈에서 봤었다. 다른 문맥에서는 의미가 달라진다. 별표는 "의 주소"와 반대의 동작을 한다. "그 주소로 가줘"라는 의미이다. &의 의미가 주소가 뭔지 물어보는 것이라면, *은 그 주소로 가달라는 의미이다. 주소가 아니라 n의 값을 출력하고 싶다면, 문자 그대로 n의 값을 출력하고 싶다면 %i라고 써뒀으니 말 그대로 이 연산을 되돌릴 수 있다. 어리석은 짓이지만 설명을 위해서 &앞에 *을 붙인다면 *&n이 된다. 왜일까? &은 주소가 뭐냐고 묻는 것이고 *는 그 주소로 가달라는 것이다. 즉, 즉각적으로 연산을 원래대로 돌리는 것이다. 실제로 이렇게 쓰진 않을 것이다. 하지만 이런 식으로 우리가 하는 기본적인 연산들에 대해 알 수 있다.
#include <stdio.h>
int main(void){
int n = 50;
printf("%i\n", *&n);
}이를 실행해보면 50이 출력된다. 주소를 출력하는 게 아니다. 주소를 돌려받고 다시 그 주소로 가서 50을 다시 볼 수 이쓴 것이다.
오늘 배운 내용이 암호처럼 느껴질 수도 있지만, &는 주소를 가져오고 *는 그 주소로 간다.
Q.주소를 프로그램에 직접 사용할 수 있나요?
예를 들어 0x12345678라는 주소를 기억하여 이 주소를 프로그램에 직접 쓸 수 있다. 그리고 그 주소로 가라고 할 수도 있다. 그러면 문법은 조금 달라진다. 형 변환은 해야 하지만 충분히 가능하다.
Q. 만약 변수의 자료형을 모른다면 어떤 형식 지정자(%?)를 사용해야 하나요?
짧게 답하면 직접 결정해야만 한다. 컴퓨터에게 메모리는 0과 1이다. 그것을 어떻게 표현할지는 여러분에게 달려있다. 그게 뭔지 모른다면 추정하거나 컴퓨터에게 무엇이든 알려줘야만 한다. char, float, int 또는 어떤 것이든. C에서 자료형을 알려주는 기능은 없다.
summary
16진수
- 0x123456ff 와 같이 표현할 수 있다.
- 메모리의 위치를 나타낼 때 사용한다.
- 2진수의 4자리(2^4 = 16)를 16진수로 1자리 표현 가능
=> 따라서 1byte의 2진수는(8bit) 2개의 16진수로 변환되기 때문에 정보를 표현하기 매우 유용하다.
&n
- ~의 주소를 의미하는 연산자
- 형식 지정자 %p 와 함께 쓰면 주소를 출력할 수 있다.
*n
- 그 주소로 간다는 것을 의미하는 연산자
- 해당 변수의 자료형에 맞는 형식 지정자와 함께 사용하면 그 주소에 들어있는 값을 출력할 수 있다.
2. 포인터
들어가기 전에
앞서 배운 메모리 주소를 직접 관리하기는 쉽지 않을 수 있습니다. C에는 포인터 라는 개념을 통해서 변수의 주소를 쉽게 저장하고 접근할 수 있게 해줍니다. 포인터가 무엇인지, 어떻게 사용하는지에 대해 배워보겠습니다.
학습 목표
포인터 변수를 정의하고 사용할 수 있습니다.
핵심 단어
- 포인터
학습하기
더 나아가 정보를 어디에 저장할 수 있는지 정확하게 알아보자. 코드를 바꿔보면 주소나 변수를 저장할 수 있다. 여기 굳이 &를 붙일 필요가 없다. 프로그램을 다음과 같이 바꿔보자.
#include <stdio.h>
int main(void){
int n = 50;
int *p = &n;
}p라는 새로운 변수를 선언하고 그 안에 n의 주소를 저장해보자. 방금 했던 거다. &n으로 n의 주소를 가져오지만, 조금 다르게 해주어야 한다. 변수의 이름을 포인터라는 의미로 p라고 했었다. 만약 어떤 변수에 주소를 저장하고 싶다면 그 변수의 자료형 뿐만 아니라 별 연산자 또한 써줘야만 한다. 매우 혼란스러울 수 있는데, 다른 문맥에서 이것은 포인터가 된다.
n의 자료형은 int이다. 첫 주에서 배운 내용이다. 유일하게 달라진 점은 다른 자료형이 생겼다는 것인데, 바로 포인터이다. 포인터는 별로 표시하고, int는 이 포인터가 가리키는 값이 int라는 말이다. 나중에 보겠지만 float 포인터도 쓰고, char 등 다양한 자료형에 대한 포인터를 쓸 것이다.
여기서는 p는 변수이고, int를 가리키는 포인터라는 의미이다. 다시말해 int의 주소이다.
#include <stdio.h>
int main(void){
int n = 50;
int *p = &n;
printf("%p\n", p);
}이 정보로 무엇을 할 수 있을까? 둘 중 아무거나 출력해보자. 먼저 주소를 출력해보자. 이를 출력해보면 "0x7ffd2160ae3c"라는 어떤 암호 같은 것이 보인다. 이전( 1)메모리 )과 다른 값이다. 그 이유는 최근 컴퓨터는 보안상 문제로 메모리를 여기저기로 바꾸기 때문이다. 어쨌든 여전히 암호 같은 16진수 주소이다.
만약 설명을 위해서 주소를 출력하지 않고 ( 왜냐하면 오늘 이후로는 변수들이 어디에 위치하는지 신경 쓰지 않을 것이기 때문에 ) p의 값이 아니라 p가 가리키고 있는 주소에 있는 값을 출력하려면 어떻게 바꾸면 될까?
#include <stdio.h>
int main(void){
int n = 50;
int *p = &n;
printf("%i\n", *p);
}p에 저장된 주소로 어떻게 갈까? p가 아닌 *p를 출력한다. 또한 형식 지정자도 또한 int로 작성해보자(%i). 즉 우리는 int값을 출력해달라고 한다. 그리고 출력하려는 int는 p에 있는 값이다. *는 가리키는 주소 p로 가라는 의미를 나타낸다.
위와 같이 코드를 작성한 후 실행시키게 되면 다시 50이 출력하게 된다.
지금까지는 왔다 갔다만 하며 사실 아직 아무것도 안했다. 배우고 적용해본 후 또 반대로 해보면서 두 가지 연산자(*와 &)를 살펴 보았다.
주소나 포인터에 대한 질문
Q. understand?
n의 주소를 p안에 저장한다. 그리고 p는 int를 가리키는 포인터이다.
다르게 말해보면, p는 어떤 정수의 주소인데, 그 숫자는 n이다.
Q. int *p대신에 int p = &n을 적는다면?
clang 컴파일러가 경고한다. 왜냐하면 주소를 저장하려고 하기 때문이다. 1 2 3 4 5 6 7 8 같은 정수가 아니고. 사실 숫자이긴 하지만, clang 컴파일러는 똑똑해서 주소는 반드시 포인터에 저장해야 한다. int형에 저장할 수 없다.
학습 계속하기

이제 그림으로 보자. 이게 우리 컴퓨터 메모리라면, 이전에 봤던 화면을 꺼내 두 줄이 무엇을 하는지 직접 보자.

첫 주에 했던 것처럼 n이라는 변수에 50을 저장하고, 그리고 p라는 변수 안에 n의 주소를 저장하자. 새로운 내용이다. 어떻게 될까? 메모리 속에 n을 다시 표시해보자.

n은 메모리 어딘가에 존재한다. n이라고 부르고, 값은 50을 가진다.

50은 임의의 위치지만, 0x12345678에 있다고 가정해보자. 메모리 어딘가이다.
이 그림에서 p는 뭘까? p또한 변수이기 때문에 bit로 데이터를 저장한다.

여기 위쯤에 있다고 가정하자.
p라고 불리고, 가지고 있는 값은 뭘까? 말 그대로 0x12345678이라는 변수 n의 주소이다. 이게 다다. 사실 굉장히 기초적인 내용이다.

사실 포인터는 추상화를 위해 사용한다. 바로 확인할 수 있다. 나머지 메모리는 없고 오직 두 값만 있다고 하면, 여기 큰 네모는 변수 p를 나타내고 주소를 저장한다. 아래 다른 네모는 변수 n을 나타내고 숫자 50을 저장하고 있다.

정확하게 말하자면 우리는 n의 주소가 뭔지 궁금하지 않다. 접근만 하면 된다. 따라서 컴뮤터 과학자는 주소 자체를 일일히 적지 않고, 즉 우리가 적은 것처럼 적지 않고 바로 화살표를 그려서 p가 50을 가리킨다는 개념을 표현한다. 이제 실제 주소는 신경 쓸 필요가 없다.

이를 비유 들어보자. 예로 들면 우편함이 있고 주소가 123이라고 하자. 123 안에 뭐가 있나? int형 변수 n이 있는데, 저장하고 있는 값은 50이다. 여기 50이라는 정수가 이 변수 안에 있다. 다른 우편함은 n이 아닌 p라 하고 456이라는 주소에 있지만 크게 의미는 없다.
만약 이 포인터 변수 p가 저기 있는 정수형을 가리킨다면 이 문을 열면 뭐가 나올까? 화살표가 n이 저기 있다고 가리키고 있을 것이다. 이 기초적인 수준에서 정확히 말하자면 이 우편함엔 뭐가 있어야 할까? 변수 n의 주소가 0x123이라면? 이 우편함에는 주소 123이 있을 것이다.

마치 보물지도 같다. 어떤 값을 얻으려면 123에 가야하는데, 그 값은 50이구나 하는 거다.

이게 차이점이다. 이 정수는 여기 정수형 변수 안에 존재하고, 이 주소는 포인터 변수 p 안에 있지만 개념적으로는 이 변수가 다른 변수를 가리키는 것이다. 가상의 빵 조각을 흩뿌두는 것이다.
앞으로 이 기능이 얼마나 강력한지 보게 될 것이다. 메모리에서 다른 곳을 가리키고 또 다른 곳을 가리키게 되면, 아주 정교한 자료형을 만들 수 있게 된다. 가계도나 배열 등 들어봤을 만한 것들이 있는데, 못 들어 봤더라도 다음 주에 배우게 될 것이다. 이 개념은 구글, 페이스북, 마이크로소프트와 같은 회사들이 수많은 데이터를 관리하기 위해 사용하는 알고리즘의 기초가 된다. 다음 주에 배우게 될 것이다.
Q. 포인터의 크기가 꼭 두배여야 할까요?
꼭 그렇지는 않지만 대부분 그렇게 동작한다. 최신 컴퓨터는 64bits 포인터로 사용한다. 둘째 주에 배운 long타입과 같은 크기이다. 그래서 여기 앞의 화면에서 8byte 혹은 64bits로 그렸다. 그리고 정수형은 4byte 또는 32bits로 그렸다. 현대 하드웨어가 그럴 뿐, 꼭 그럴 필요는 없다.
생각해보기
포인터의 크기는 메모리의 크기와 어떤 관계가 있을까요?
포인터의 크기는 32bits 운영체제에서는 4byte, 64bits 운영체제에서는 8byte로 일정한 크기를 갖는다.
3. 문자열
들어가기 전에
“EMMA”와 같은 문자열을 저장하기 위해서 string 이라는 자료형을 사용하였었습니다. 하지만 이는 실제로 C에서 존재하지 않는 자료형입니다. 문자열이 실제로 메모리상에 어떻게 저장되어 있는지, 문자열을 손쉽게 저장하고 접근하기 위한 방법을 배워봅니다.
학습 목표
문자열 형태의 새로운 자료형인 string이 어떻게 정의되었는지 설명할 수 있습니다.
핵심 단어
- 포인터
- 문자열
학습하기
문자열에 대해서 꽤 얘기했었다. 지금까지 작성한 프로그램 대부분은 사용자에게 어떤 글을 입력 받아 그 값을 사용했었다.
이전에 문자열에 대해서 말한 내용은 사실 선의의 거짓말이다. 오늘부터 떼기로 한 보조 바퀴는 맞다. 이제 새로운 문맥에서 문자열이 무엇인지 보자.
string s = "EMMA";여기 문자열"EMMA"가 s라는 변수에 저장되어 있다. 컴퓨터 안에서는 어떻게 보일까?
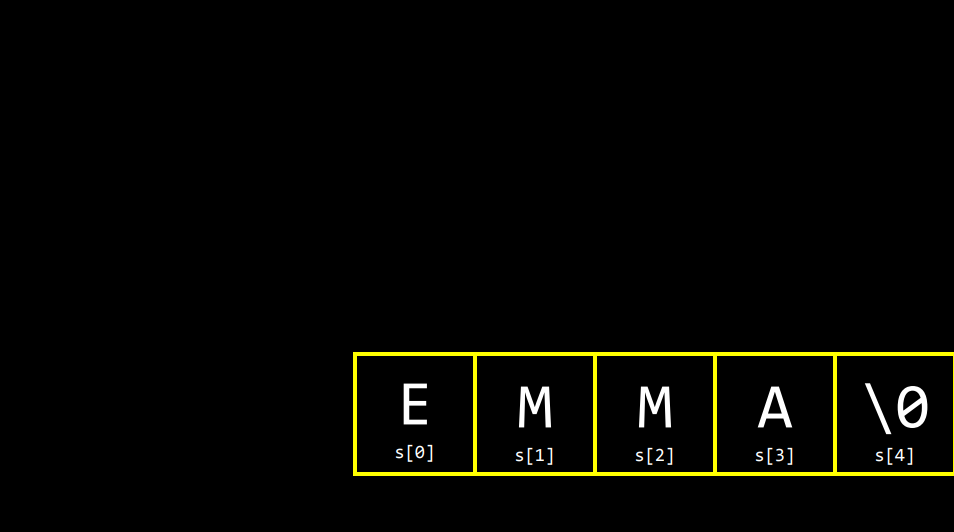
메모리 속 어딘가에 5바이트의 공간에 "E M M A" 그리고 "\0"가 있어 문자열의 끝을 구별해준다. 각 1칸인 1byte는 8개의 0 비트로 되어 있다.
EMMA가 이렇게 저장되는데, 우리가 보던 문자열 변수는 s였다. 그래서 지금까지는 문자열을 조작하려면 s를 쓰고 [0] [1] [2] [3]을 사용해서 개별문자에 접근했었다. E M M A 알파벳 각자를 말이다.

하지만 오늘 말했듯이, 각 바이트는 고유의 주소를 갖고 있다. 오늘 이후로는 주소를 신경 쓰지 않을테지만 분명히 존재한다. 예로 들어서 E의 위치는 0x123, 그 다음 M은 이로부터 한 바이트 떨어지니까 0x124, ... 0x127. 문자열은 문자 하나하나가 계속 이어지는 형태이기 때문이다.
여기서 EMMA의 이름이 메모리 0x123부터 존재한다고 보자. 그렇다면 변수 s는 무엇일까?
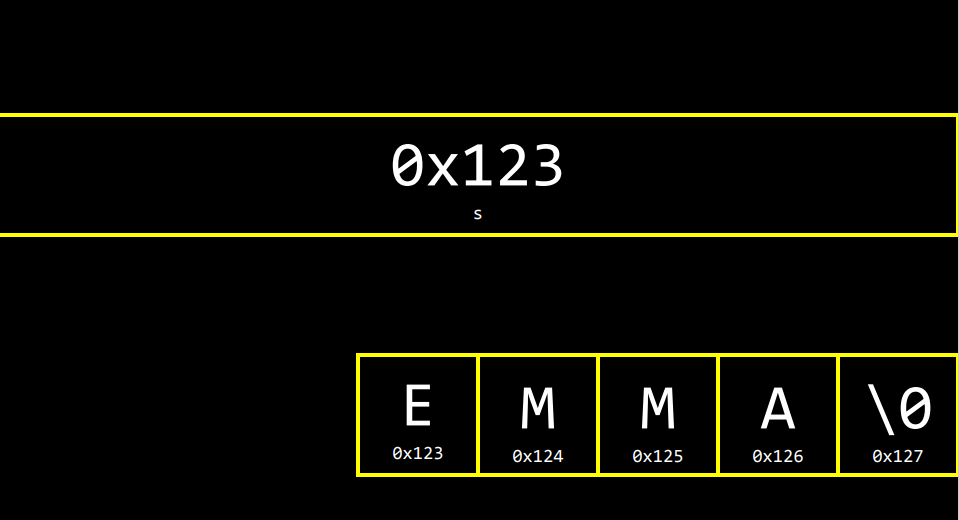
사실 s는 그냥 포인터이다. 여기 보이듯 s라는 하나의 변수이다. 그리고 0x123라는 값을 저장하고 있다. 이는 EMMA의 이름이 시작되는 주소이다. 사실 이 주솟값을 알 필요는 없다. 그래서 그냥 아래와 같이 그림으로 나타내보자.
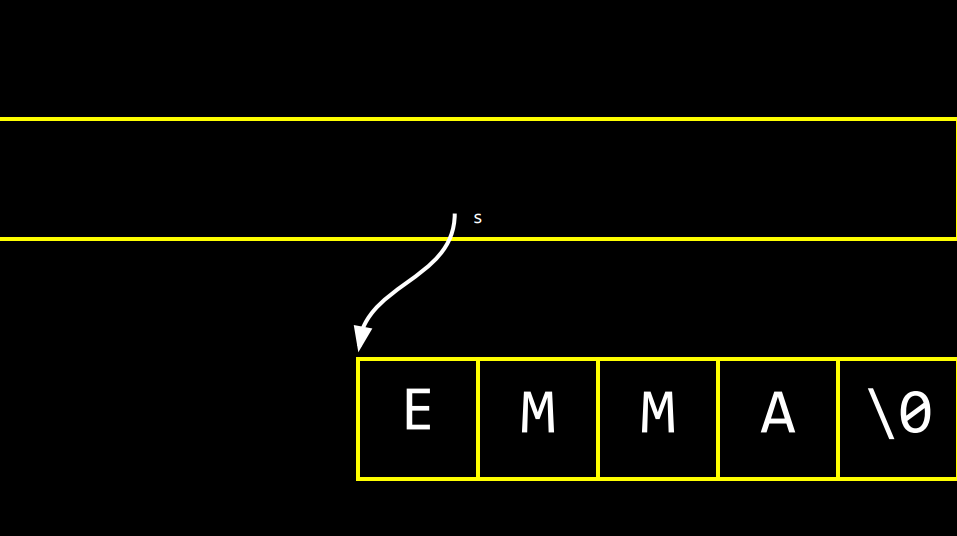
s는 포인터로, 메모리에 있는 EMMA의 이름을 가리킨다. 위치는 메모리의 어딘가에 존재한다.
여기 화살표 s가 나타내는 것은, EMMA라는 이름의 첫 글자이다. s가 EMMA의 이름의 시작인 E가 있는 위치인 0x123을 저장하고 있고, 이 내용을 화살표로 표시한다면, 어떻게 컴퓨터는 EMMA의 이름이 어디서 끝나는지 알까? 첫 글자만 기억하는데 말이다.
이는 중요하다. 문자열로 불리는 s는 M M A나 널 종단 문자에 대해 전혀 모른다. 오늘부터 s는 엄밀히 말해 첫 번째 문자가 있는 0x123라는 문자만 안다. 하지만 컴퓨터는 너무 똑똑해서 문자열의 첫 번째 글자만 가리키면, 널 종단 문자를 만날 때까지 루프를 돌면서 끝을 알아낸다.
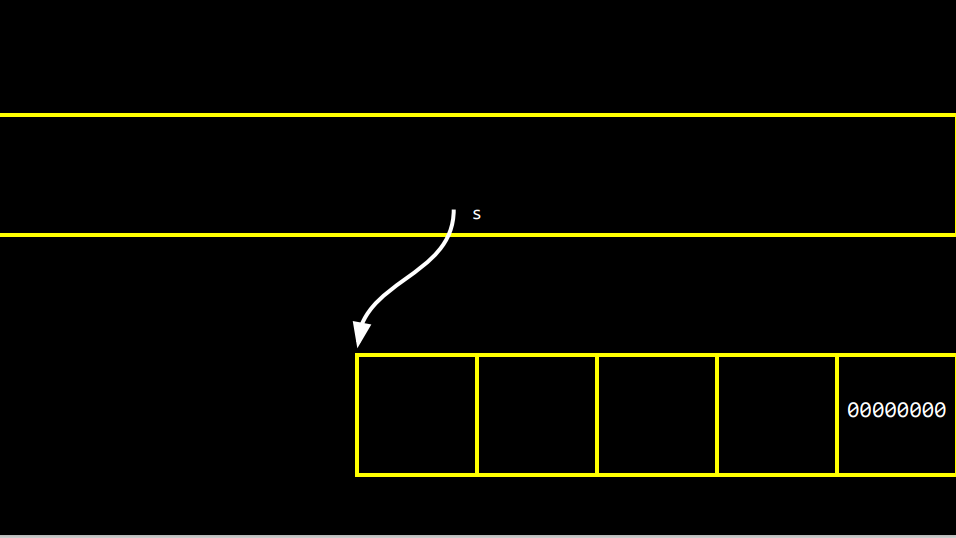
이제 더 이상 문자열(string) 같은 건 없다. 이제껏 실제 문자열을 조작해보며 흥미를 주려고 사용했다. 그렇다면 문자열은 어떻게 구현되어 있을까?
엄밀히 말해 문자열이란 무엇일까? 포인터이다. EMMA라는 이름이 저장된 변수 s는 좀 전에 숫자 50으로 봤을 떄와 비슷한 패턴으로 되어 있다. s가 여러개의 주소 중 첫 번째 문자의 주소를 저장하면 결국 그게 문자열이 된다.
정리해보자.
int n = 50;
int *p = &n위의 코드를 보자. int는 첫 주에 배운 자료형이고, int*는 오늘 배운 새로운 자료형으로, 정수가 아니라 정수의 주소를 저장한다. 그렇다면 EMMA의 이름을 담은 아래와 같이 코드는 이렇게 char*로 적을 수 있다.
char *s = "EMMA";*는 주소를 나타내고 char는 주소에 있는 값의 자료형이 char이라는 말이다. int*가 50이 저장된 변수 n을 가리키던 것처럼 같은 방법으로 char*는 문자를 가리키는 주소로 저장할 수 있다. 계속 말했듯 문자열은 문자들의 나열이다. 따라서 결국 문자열은 문자 배열의 첫 번째 바이트 주소가 된다. 그리고 마지막 바이트에는 0을 저장해 끝을 알려준다.
그렇다면 결국 문자열이란 무엇이고, cs50 라이브러리에서 보조 바퀴처럼 떼어낼 것은 뭘까? 지난주에 우리는 typedef를 배웠다. c언어에는 없지만 우리 프로그램에는 존재하는 자료형을 만들었다. 지난주에 배운 typedef 키워드를 사용해 이름이나 숫자와 같은 다양한 변수를 하나로 묶어서 person이라는 새로운 자료형을 선언할 수 있었다.
typedef struct
{
string name;
string number;
}
person;typedef은 사실 이보다도 훨씬 더 간단하게 사용할 수 있다.
typedef char *string;위와 같이 적으면,
typedef는 새로운 자료형을 선언한다는 의미이고,
char *는 이 값이 형태가 문자의 주소가 될 것이라는 의미이며,
string은 이 자료형의 이름을 의미한다.
정확히 똑같은 이 한 줄이 우리가 불러오던 cs50.h 헤더 파일에 적혀있다. string이라는 새로운 자료형을 만드는데 이는 사실 char*와 동일하다. 일종의 추상화이다. 문자의 나열을 결국에는 주소 하나로 나타낼 수 있다는 사실을 단순화시킨 것이다.
따라서 문자열이라는 자료형이 실제로 존재하지 않지만 지금까지 존재한다고 알려줬던 것이다."hello world"와 같은 메시지를 출력하고 싶은데 주소나 포인터에 대해 전부 이해하고 싶지 않을 것이다.
Q. cs50 라이브러리에 또 어떤 함수들이 구현되어 있나요?
get_string, get_int, get_float와 같은 get함수들이 있다.
string은 char *라고 했다. string은 어떤 char의 주소를 가지고 있는 변수이다. 일반적으로 여러 문자가 나열되어 있다면 첫 번째를 의미한다. 이는 둘쨋주에 했던 이야기이고,
string은 문자 하나를 가리키는 주소이다. 그리고 사람들은 문자열의 끝을 8개의 0비트로 채워진 널 종단 문자로 표현하기로 약속한 것이다. 만약 다른 프로그래밍 언어를 배우면 알겠지만 C는 비교적 기초적인 수준이다.
몇 주 후에 볼 파이썬은 모든게 아주 쉽게 동작한다. 문자열도 그냥 쓰면 되고 이런 기초적인 수준의 상세한 내용을 생각할 필요가 없다. 이유는 개념적으로 파이썬이 여기 위에 있다면 C언어는 컴퓨터 메모리에 가까운 여기 아래쯤이기 때문이다. 마법은 아니다. 문자열을 쓰고 싶다면 어디서 시작하고 어디서 끝나는지 기억하면 된다. 오늘 배운 *로 이런 개념을 코드로 표현할 수 있다.
이제 문자열을 사용해서 EMMA의 이름으로 실험해보자.
#include <stdio.h>
#include <cs50.h>
int main(void){
string s = "EMMA";
printf("%s\n",s);
}결과로 EMMA가 나온다. 이제 무엇을 바꿀 수 있을까? 먼저 할 수 있는 것은 cs50.h 를 삭제하여 string형을 쓰지 않고 이제 보조 바퀴를 뗄 것이다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%s\n",s);
}s가 문자열이라면, 엄밀히 말해 첫 번째 문자의 주소를 가지고 있으면 된다. 따라서 string 대신에 char*를 적으면 된다. 사실 양쪽에 공백을 써도 되지만, 대부분 프로그래머는 char *이름 형태로 작성한다. 굉장히 낯설지만 지난 몇 주간 해왔던 것과는 큰 차이가 없다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%p\n",s);
}이제 이것저것 할 수 있다. s가 문자의 주소라면 주소를 출력하기 위해 어떤 형식 지정자를 사용했었나? %p이다. 포인터니까. 출력해보면 어떤 주소가 출력될 것이다. EMMA의 이름은 0x42A9F2에 저장되어 있나보다. 이게 십진수로 무슨 값이든지 어쨌든 메모리 어딘가에 있다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%p\n",&s[0]);
}그럼 이번에는 어떻게 될까? 이제 내가 궁금한 것은 EMMA 이름의 첫 글자 주소이다. C에서 첫 글자만 표현하는 방법이 뭘까? EMMA는 s에 있다. s[0]일까? 이는 char이다. s[0]은 문자형이다. 따라서 여기서 s[0]의 주소를 얻으려면 &를 붙이면 된다. 따라서 &s[0]이 된다.
출력해보면 위와 같은 주소가 출력된다. 그 이유는 s의 주소는 사실상 첫 번째 문자의 주소이기 때문이다. 이를 확인해보기 위해 s[0]의 첫 번째 문자의 주소를 보면 위의 주소와 같음을 확인할 수 있다.
따라서 문자열은 여러 문자의 묶음을 추상화한 것이다. 즉, s는 그냥 주소이다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%p\n",&s[0]);
printf("%p\n",&s[1]);
printf("%p\n",&s[2]);
printf("%p\n",&s[3]);
}만일 1,2,3 번째 글자의 주소를 출력하면 어떻게 될까? 이를 돌려보자. 그렇게 되면
s[0] : 0x42A9F2
s[1] : 0x42A9F3
s[2] : 0x42A9F4
s[3] : 0x42A9F5
각각의 주소가 위와 같음을 알 수 있다. 주소가 1바이트 씩 차이나는 것을 확인할 수 있다.
문자열을 조작할 때 사실 우리는 우리 우편함을 확인하고 있었다. 메모리 속 여러 주소를 찾아가서 그 속의 값을 조작했던 것이다.
생각해보기
string 자료형을 정의해서 사용하면 어떤 장점이 있을까요?
포인터 개념을 알지 못해도 쉽게 문자열 입력이 쉬워지게 된다.
4. 문자열
들어가기 전에
두 문자열이 같은 내용을 담고 있는지 어떻게 비교할 수 있을까요? 우리가 배운 문자열 자료형을 사용해서 바로 직접적으로 비교가 가능할까요? 문자열이 저장되어 있는 방식을 자세히 들여다보면서 해서 위와 같은 질문에 대한 답을 해 봅니다.
학습 목표
문자열이 저장되어 있는 방식에 근거해서 문자열을 비교하는 방법에 대해 설명할 수 있습니다.
핵심 단어
- 문자열
학습하기
결국 이 모든 과정이 주소 단위로 이뤄진다면, 다음을 보자.
주소 s에 뭐가 있는지 출력해보면, 즉 s에 있는 주소로 가면 그 안에 뭐가 있을까? EMMA이름의 첫 글자인 E가 들어있다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%c\n", *s);
}s는 어떤 문자의 주소이고, s로 찾아가면 뭐가 있을가? 아마 EMMA의 E가 들어있을 것이다. 해당 주소로 가서 그 내용물을 출력하기 때문이다. s가 이름 첫 글자의 주소라면 *s는 그 문자로 가달라는 것이다.
이는 다른 글자로도 해볼 수 있다.
#include <stdio.h>
int main(void){
char *s = "EMMA";
printf("%c\n", *s);
printf("%c\n", *(s+1));
printf("%c\n", *(s+2));
printf("%c\n", *(s+3));
}우선 s로 찾아가서 두 번째 글자를 얻으려면 어디로 갈까? +1를 하면 된다. 기본적인 산수이다. +1을 하면 두 번째 글자가 된다. 위와 같이 실행하면 E M M A가 출력된다. 기초적인 수준의 방법이다.
여기서 대괄호는 무슨 의미일까? 컴퓨터 과학에서는 구문 설탕이라고 한다. 프로그래머에게 유용한 기능을 의미한다. s[0]이나 s[1]처럼 적으면 컴퓨터 내부에서 clang 컴파일러가 대괄호 표현식을 *(s+1)와 같은 형태로 바꿔주는 것이다. 내부에서 연산을 해주는 것이다.
Q. 왜 s를 출력하면 한 글자가 아니라 전체 문자열을 출력하나요?
이는 printf의 형식 지정자가 해준다. printf에서 %s를 사용해서 출력을 요청하면 그 주소로 가서 첫 글자만 출력하지 않고 다음 문자를 계속 출력하는데, 널 종단 문자까지 수행한다.
우리가 사용한 printf와 %s는 어떤 일을 해야 하는지 알고 있었던 것이다. 포인터 연산은 주소를 가져와서 1 2 3을 더하는 것처럼 계산을 하는 것이다.
이번에는 문자열을 다룰 때 실수를 줄이도록 하는 몇 가지를 알아보자.
보조 바퀴를 이용하여 두 정수를 비교하는 프로그램을 빠르게 만들어 보자.
#include <stdio.h>
#include <cs50.h>
int main(void){
int i = get_int("i: ");
int j = get_int("j: ");
if(i == j){
printf("Same\n");
}else{
printf("Different\n");
}
}<결과>
i: 1
j: 1
Same
i: 1
j: 1
Different
이번에는 숫자 말고 다른 걸 비교해보자.
#include <stdio.h>
#include <cs50.h>
int main(void){
string s = get_string("s: ");
string t = get_string("t: ");
if(s == t){
printf("Same\n");
}else{
printf("Different\n");
}
}<결과>
s: EMMA
t: EMMA
Different
왜 다를까? 각각 다른 곳에 저장되어 있기 때문이다. get_string으로 문자열을 입력받아 s라고 하고 또 다른 문자열을 받아 t라 하면 메모리 두 덩어리를 받는다. 사용자가 동일한 내용을 입력할 순 있지만, 이들이 같은 곳에 있다는 의미는 아니다.
지금 상황을 그려보자.
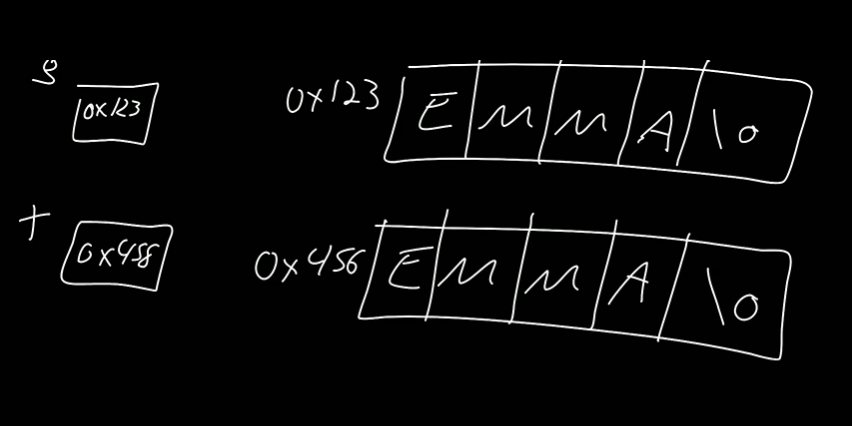
변수 s와 t를 상자로 그려보았다. 그리고 우리가 입력한 EMMA는 메모리 어딘가에 E M M A \0으로 배열처럼 존재한다. 다시 t에 EMMA를 입력하면 get_string에 의해 다른 메모리 공간에 적히게 된다. get_string은 이렇게 동작하도록 구현되어 있다.
s와 t에는 뭐가 저장될까? 첫 번째 공간의 주소를 0x123이고 두 번째 메모리 공간은 0x456이라고 하자. 그러면 s에는 0x123이 저장되고 t에는 0x456이 저장된다.
s가 t와 같은지 물어보면 같나? 아니다. 0x123와 0x456을 비교한다. 컴퓨터는 먼저 그 주소로 찾아가지 않는다. 우리가 시키기 전까지는 말이다.

다르게 표현하자면 이 상자 안에 값을 써두는 대신에 화살표를 이용하여 그 값을 가리키는 포인터를 그리자. 실제 주소는 전혀 상관없으니까.
이런 이유로 저번 주에 문자열을 비교하려면 하나씩 비교해야 하므로 안된다고 말했었다. 사실이다 하지만 엄밀히 말해 우리가 비교한 것은 "두 변수의 주소"이다.
Q. 컴퓨터는 포인터가 어디에 있는지 어떻게 아나요?
string s = get_string("s: ");
string t = get_string("t: ");지금까지 get_string로 문자열을 입력받을 때마다 우리는 위의 코드와 같이 s라는 문자열 변수에 할당할 것이다.
하지만 cs50 라이브러리를 없애면, 문자열 s은 char *가 되고, t 또한 char *가 될 것이다. 보조 바퀴를 없애고 string을 바꾸면 된다. char *s는 s가 문자의 주소를 저장한다는 의미이고, char *t는 t가 문자의 주소를 저장한다는 의미이다.
char *s = get_string("s: ");
char *t = get_string("t: ");저희가 둘째 주부터 get_string을 사용했는데, 이 함수가 반환하던 값은 뭐였을까? 어떤 값을 돌려줘야 할까? 첫 글자의 주소이다. get_string을 호출할 때마다 메모리 어딘가에서 입력한 문자 크기만큼의 공간을 찾아 입력한 글자를 넣어둔다. 그리고 메모리 공간의 첫 바이트 주소를 반환하게 되어 있다. 즉 get_string은 호출될 때마다 포인터를 반환한다.
이제 변수를 출력해보자.
#include <stdio.h>
#include <cs50.h>
int main(void){
char* s = get_string("s: ");
char* t = get_string("t: ");
printf("%p\n", s);
printf("%p\n", t);
}위를 컴파일한 후 실행해보면
<출력>
s: EMMA
t: EMMA
0xed76a0
0xed76e0
둘은 몇 바이트 떨어져 있음을 확인할 수 있다. 즉, 두 문자열의 주소값이 다르다.
5. 문자열 복사
들어가기 전에
문자열이 메모리에 저장되어 있는 방식에 대해 배웠습니다. 그렇다면 이미 저장되어 있는 문자열을 다른 곳에 복사하려면 어떻게 해야 할까요?
학습 목표
문자열을 복사할 수 있습니다.
핵심 단어
- malloc
학습하기
다른 예제를 보자. 사용자로부터 문자열을 입력받고 이를 t로 복사한 뒤 문자열을 대문자로 바꿔보자.
#include <stdio.h>
#include <ctype.h> //toupper()
#include <cs50.h>
int main(void){
char *s = get_string("s: ");
char *t = s; //문자열을 복사하지 않고 주소를 복사하게 된다.
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}문자열을 출력해보면,
s: emma
Emma //s
Emma //t
왜인지 둘 다 대문자가 되었다. 보시다시피 소문자였던 emma가 s와 t 내부에서 모두 대문자로 바뀌었다. 버그인가? t만 바꿨는데 어떻게 s까지 대문자로 바뀌었을까?
s를 복사한다고 했는데, 말 그대로 s를 복사하고 있었다. s는 오늘부로 주소이다. string인 s와 t는 사실상 char *이기 때문에 주소를 복사한 것이다.
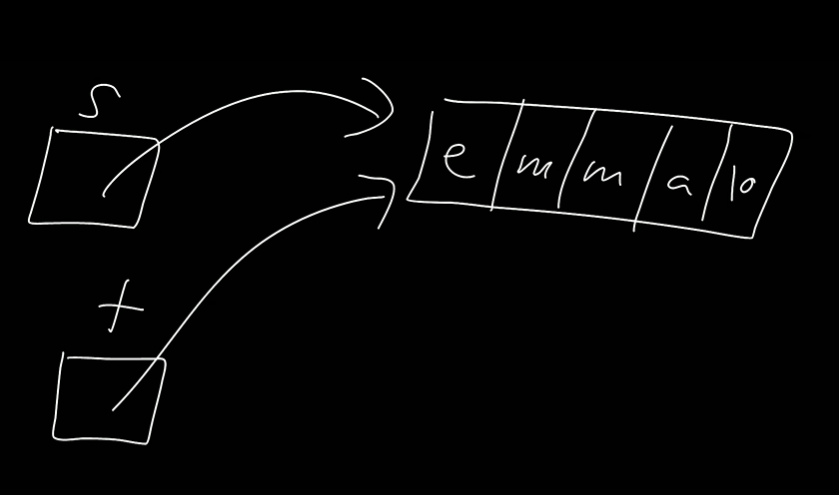
그렇다면 이전 그림으로 돌아가서, 이번에는 배열 속에 소문자로 emma를 적었다. e m m a \0를 get_string을 메모리 어딘가에 저장했다. 그리고 변수 s에 그 위치를 저장했다. 실제 주소는 중요하지 않으므로 화살표로 나타내었다.
t라는 두 번째 변수를 만들어서 s에 대입하면 s안에 있는 화살표를 복사하여 t에 저장하게 된다. 즉, 같은 곳을 가리키게 되는 것이다.
화살표를 사용하지 않았다면 0x123이라 적었을 것이다. 그렇다면 s와 t안에 모두 0x123을 적었을 것이다.
코드상에서 t의 첫 글자를 가져와 대문자를 바꾸라고 하면 t의 첫 글자는 e이다. 또한 s안에 있는 첫 글자도 e이다. 동일한 e인 것이다. 즉 지금까지 다른 자료형에서 했던 것처럼 t = s 라고 적으면 문자열을 복사하지 않는다. 임시 변수나 무언가를 복사할 때에는 됐었지만.
그렇다면 서로 다른 메모리 공간에 emma를 복사하려면 어떻게 해야 할까? 메모리를 추가로 사용하여 EMMA와 동일한 크기의 변수를 만들고 s안에 있는 글자를 하나씩 t로 복사하는 것이다.
#include <stdio.h>
#include <stdlib.h> //malloc()
#include <cs50.h>
int main(void){
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1); //malloc() : 할당 받을 메모리 크기(byte)를 입력
//문자열크기 + 널 종단 문자(1)
for (int i = 0; i < strlen(s); i++){
t[i] = s[i];
}
}위 코드에서 무엇이 잘못 되었을까? 여기에는 작은 버그와 비효율성이 있다.
(1) 코드 속 for문이 비효율적이다.
for (int i = 0, n = strlen(s); i < n; i++){
t[i] = s[i];
}간단한 최적화 기법으로 n을 정의하고 s의 길이를 저장하여 작성할 수 있다. 그리고 i가 n보다 작으면으로 바꾸자. 이로 인해 설계를 개선했다. 더 효율적이고 시간을 덜 낭비한다.
따라서 n = strlen(s) 로 정의하여 사용하자.
(2) 널 종단 문자를 복사하지 않는다.
문자열을 순환한다면 위의 방식이 맞다. 하지만 문자 길이만큼 반복하지만 그 이상은 하지 않는다. 따라서 다음과 같은 경우에 한 번 더 반복해야만 한다. 왜냐하면 e m m a 네 글자만 복사할 뿐만 아니라 5번째 글자인 널 종단 문자까지 복사해야하기 때문이다. 이 경우 의도적으로 평소보다 한 번 더 반복하여 EMMA의 5바이트를 복사해야 한다. 4개가 아니라.
for (int i = 0, n = strlen(s); i < n + 1; i++){
t[i] = s[i];
}따라서, i < n + 1로 변경해야 한다.
#include <stdio.h>
#include <ctype.h> //toupper()
#include <cs50.h>
#include <string.h> //strlen()
int main(void){
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1);
for (int i = 0, n = strlen(s); i <= n; i++){
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}이제 emma를 대문자로 바꾼 후 %s를 이용해 s와 t 문자열을 출력해보았다.
첫 코드와 뭐가 다를까? 달라진 것은 malloc을 사용해서 EMMA를 복사하는데 필요한 메모리 공간을 할당받고 for문 루프를 통해 실제로 값을 복사한다.
<실행 결과>
s: emma
emma
Emma
짜잔! malloc을 이용해 s가 아닌 t만 대문자로 바꿨다.
Q. malloc을 사용하면 요청한 바이트 크기만 할당하고 위치는 신경쓰지 않나요?
malloc은 요청한 크기만 할당할 뿐 위치는 중요하지 않는다. 우리도 위치는 신경쓸 필요가 없다. 왜냐하면 주소를 받으면 c코드를 사용해서 그 위치로 갈 수 있으니까.
이제 마무리해보자. 문자열 복사는 자주 하는 작업이기 때문에 이 루프를 직접할 필요가 없다. 아래처럼 코드를 개선하여 간단하게 바꿀 수 있다.
문자열에 대한 문서를 보면 strcpy라는 함수가 있다. 이름에 모음이 없다. t에 s의 내용을 복사할 수 있다. strcpy는 누군가가 이미 작성해 놓은 코드로 우리가 앞서 작성한 루프를 사용하여 작성했을 것이다. 코드가 조금 간단해진다.
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1);
t = strcpy(s);
Q. 마지막 종단 문자를 복사하지 않으면 어떻게 되나요?
아무도 모른다. s와 t를 출력하려고 할 때 프로그램이 앞서 뭔가 써둔 게 있다면 그것까지 출력하려고 할 것이다. 종단 문자가 없다면 그 뒤 내용까지 다 출력하게 될 것이다.
계속 배울텐데 변수의 값을 초기화하지 않으면 "쓰레기값"이라고 한다. 운이 좋아서 0일 수도 있지만, 메모리에 이미 0과 1이 잔뜩 있다면 그 쓰레기값을 출력할 것이다.
Q. string이 없다면 strcpy나 strlen함수는 왜 있나요?
C는 string을 char *로 부른다. 문자열을 string이라 하지 않는다. 이 수업과 대부분 다른 곳에서는 일반적으로 문자의 나열을 string이라고 부른다.
앞으로 string이라는 말을 쓴다면 오늘부터는 char *로 바꿔 생각해도 문제 없을 것이다.
생각해보기
배운 바와 같이 메모리 할당을 통해 문자열을 복사하지 않고, 단순히 문자열의 주소만 복사했을 때는 어떤 문제가 생길까요?
문자열의 주소만 복사한 경우, 두 문자열이 가리키는 주소가 같으므로 한 문자열을 변경한 경우 다른 문자열도 함께 변경 된다. 따라서 두 문자열이 서로 의존적이기 때문에 독립적인 기능을 하지 않아 문제가 발생한다.
따라서 이를 보완하기 위해 메모리 할당을 사용하게 되면 문자열의 주소를 복사하지 않고 문자열을 복사하게 되므로 두 문자열을 독립적으로 사용할 수 있게 된다.
6. 메모리 할당과 해제
들어가기 전에
메모리를 할당한 후에 저장한 값이 필요가 없어지고 나서는 어떻게 해야 할까요? 유한한 메모리를 효과적으로 관리하기 위해서 우리가 프로그램을 작성하며 할당한 많은 메모리들을 어떻게 관리해야 하는지에 대해 배워보겠습니다.
학습 목표
메모리를 할당하고 해제할 수 있습니다.
핵심 단어
- free
- valgrind
free
좀 전에 배운 새 기능인 malloc이라는 메모리 함수 기능을 살펴보자.
get_string은 사용자로부터 입력받은 문자열의 주소를 돌려준다. malloc도 비슷한 값을 돌려준다.
char *t = malloc(string(s) + 1);이 정도 크기의 메모리를 요청하면, 여기는 emma와 종단 문자로 총 5byte였는데, malloc도 똑같이 할당한 메모리의 "첫 바이트 주소"를 돌려준다.
메모리 할당이란, 메모리 일부분을 가져와서 그곳을 가리키는 포인터를 주는 것이다. 그 주소는 우리가 기억해야 하므로 여기에서처럼 t에 저장한다.
#include <stdio.h>
#include <ctype.h> //toupper()
#include <cs50.h>
#include <string.h> //strlen()
int main(void){
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1);
for (int i = 0, n = strlen(s); i <= n; i++){
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}안타깝게도 이제 보조 바퀴가 없기 떄문에 스스로 더 많은 일을 해야 한다. 사실 이 코드에는 버그가 있다. 메모리를 할당받았지만, 해제하지는 않았다. malloc의 반대는 free라는 함수이다. 이 함수는 할당되었던 메모리를 다시 반환한다. 그래야 프로그램이 더 많은 메모리를 사용할 수 있게 된다.
짧게 얘기하면 우리 컴퓨터가 어떤 프로그램을 돌리면서 점점 더 느려지면서 메모리가 부족하다고 에러 메시지를 띄운다면, 그 프로그램의 작성자가 malloc을 호출하고 계속 호출하면서 메모리를 많이 할당하지만 전혀 해제하지 않았기 때문이다. 프로그램과 컴퓨터의 메모리가 이렇게 바닥나게 된다. 따라서 사용하지 않는 메모리는 해제하는 것이 좋다.
valgrind
이런 실수를 어떻게 찾을 수 있을까? 우리를 위한 디버깅 도구가 있다. cs50에 한정된 도구가 아닌 valgrind이라는 프로그램이다.
만일 위의 코드에 valgrind라는 프로그램을 돌려보자.
valgrind ./파일명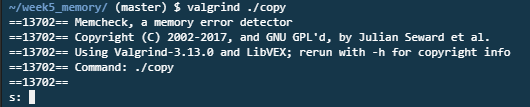
난해한 출력이 나오고 s를 입력하라고 나온다.
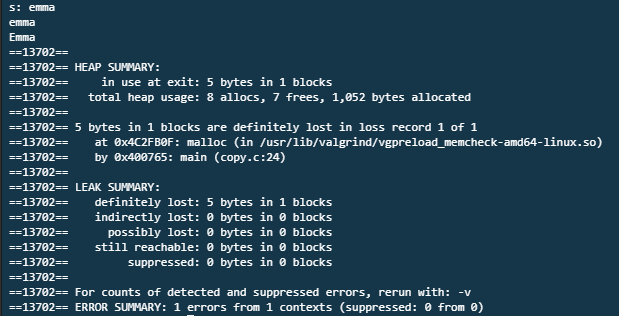
emma를 소문자로 입력하고 엔터를 누른다. 그럼 여러 요약이 출력되고 여기저기 에러가 나온다.
힙 메모리 요약에는 "한 블록의 5 바이트가 첫 번째 손실 기록에서 손실되었습니다".
또 누수 요약에는 "한 블럭의 5 바이트가 누수되었습니다"라고 한다.
이건 리눅스라는 업계에서 흔히 쓰이는 운영체제의 한 프로그램이다. 출력되는 내용 중 봐야할 부분이 많지만 우선 중요한 부분에만 집중해보자. 메모리 누수. 좋지 않다.
어디서 메모리 누수가 나는지 알 수 있을까? help50을 사용해보자. help50은 valgrind 결과를 분석해준다.
help50 valgrind ./파일명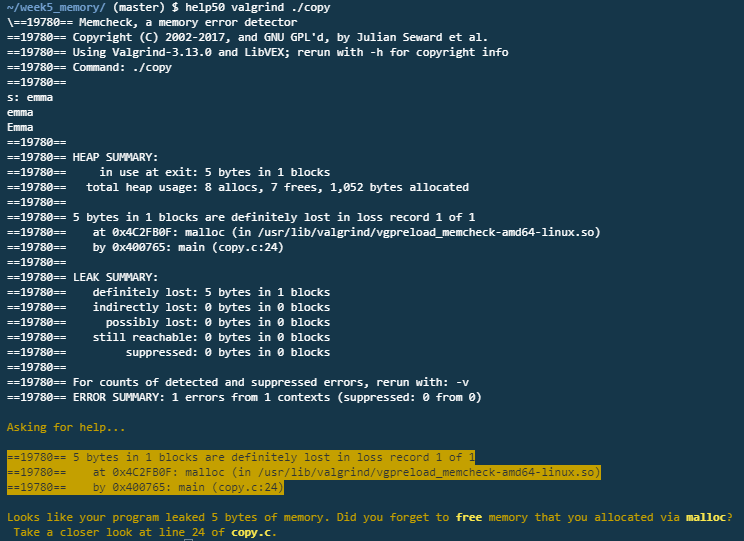
위 코드를 실행하게 되면 도움이 될 만한 메시지를 help50가 노란색으로 알려준다. 프로그램에서 5byte의 메모리가 세는데, 혹시 malloc으로 할당받은 메모리를 해제하였는지 묻는다. 그리고 copy.c의 24번째 줄을 다시 보라고 한다.
우리는 이걸 여러 번 돌려보면 위쪽을 보고 에러가 뭔지 살펴볼 수 있을 것이다. 여기 나오는 메시지가 전부이다. 글은 많지만 결국 어디를 봐야 하는지 제대로 알려준다.
코드의 24번째 줄을 보자. 24번째 줄에서 malloc을 사용하여 메모리를 할당하였다. 해답은 굉장히 간단하다. 아래로 가서 free(t)를 적는다. malloc이 할당해 준 메모리의 주소이다. 할당된 메모리를 반대로 해제하는 것이다.
free(t);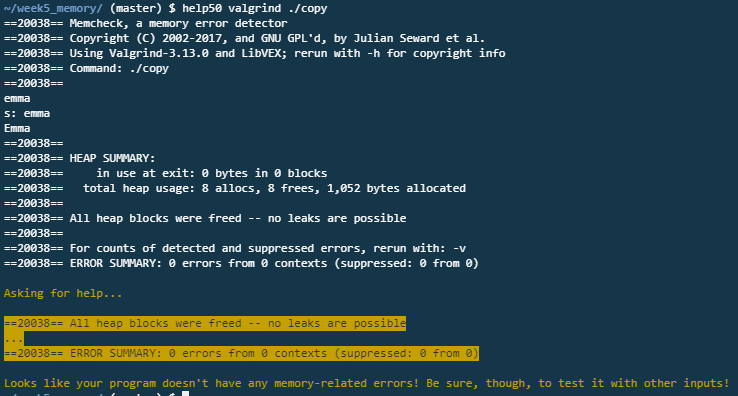
이를 실행해보면 사실 실행 결과는 똑같다. 여전히 제대로 작동한다. 하지만 실수를 찾기위해 valgrind로 실행해보면 이번에는 메모리 누수 요약에 0개의 블럭에 0바이트라고 한다. 모든 게 잘 동작해도 많은 내용이 출력은 된다. 그래도 메모리가 새고 있다는 말은 이제 보이지 않는다.
앞으로 이런걸 계속 보며서 복잡한 버그를 잡는 데 사용할 것이다. 이는 에러를 찾는데 도와주는 여러 도구 중 하나이다.
버퍼 오버플로우
다른 걸 하나 해보자.
#include <stdlib.h>
void f(void){
int *x = malloc(10 * sizeof(int));
x[10] = 0; //ERROR! 10번째 없음. 0~9임. 버퍼 오버플로우 발생.
x[1000] = 0; //ERROR! 할당한 메모리를 벗어남
//valgrind를 이용하면 에러 발생한 것을 볼 수 있음.
//help50 valgrind ./memory
}
int main(void){
f();
return 0;
}
4번째 줄은 무엇을 의미할까? malloc함수를 이용하여 메모리의 주소를 x라는 포인터에 저장한다.
여기서 sizeof를 쓰고 괄호 사이에 자료형을 쓰면 크기를 알려준다. int는 4byte, long형은 8byte, char형은 1byte라고 알려준다. 일일이 숫자를 기억하지 않고 동적으로 알아내는 방법이다. 정수형 크기를 10개 달라고 하고 정수형은 4byte이니, 4*10 즉 40byte의 메모리를 요청한다. 사실상 정수를 저장하는 메모리의 배열이다. malloc은 그 메모리 공간의 시작 주소를 반환할 것이다.
5번째 줄이 왜 문제일까? x[10]에 0을 저장하고 있다. 왜? 그냥. 하지만 10번째는 없다. 10개의 정수가 있다면 0부터 9까지고 10은 없다. 이는 버퍼 오버플로우의 예시이다. 메모리를 이야기하거나 혹은 메모리 배열을 다룰 때 여기서는 연속된 공간에 정수가 10개가 있는데 그 공간을 넘어 접근한다면 이런 상황을 버퍼 오버플로우라고 한다. 여기서는 버퍼는 배열이다.
이렇게 하면 더 명확하다. 5번째 줄과 같이 1000번째 배열에 접근하려 하면, 분명 이건 내가 할당한 메모리가 아니다. 배열이 경계를 넘고 있다. [10]의 경우 한 걸음 더 간 것이다.
valgrind ./파일명valgrind의 장점이 여기에 있다. 이를 컴파일한 후 위와 같이 입력하면
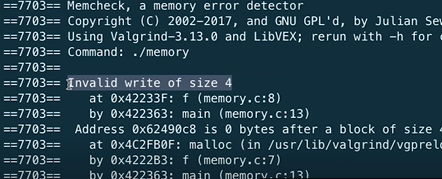
보시다시피 4byte를 잘못 적고 있다고 한다.
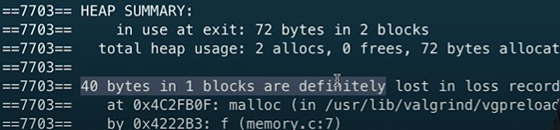
또 아래를 내려보면 한 블록 안에 40바이트가 손실 되었다고 한다.
그럼 우선 두 번째부터 고쳐보자. 왜 40바이트가 새고 있을까? 해제하지 않았기 때문이다. 따라서 끝에서 free(x)를 입력하여 메모리를 해제해주면, 즉 메모리를 다 사용한 후 해제하면 된다. 사실 여기서는 사용도 하지 않지만 말이다..
free(x);위 코드 입력한 후 다시 valgrind를 살펴보면 두 번째 문제는 나타나지 않는다.

하지만 문제는 여전히 남아있다. 첫 번째 문제를 다시 보자. 이럴 때 다양한 자료형과 그 크기를 알고 있으면 유용하다. "4 바이트에 유효하지 않은 쓰기". 프로그램에서 "쓰기"는 값을 바꾼다는 뜻인데, 아래 코드와 같이 8번 줄을 지목했다. 정수형의 크기는 얼마인가? 4byte이다. 임의로 0으로 바꾸려고 했으나 우리가 할당하지 않은 메모리 영역을 접근하려고 했다. 우리는 정수형 10개 크기에 해당하는 40 바이트를 요청하였고, 인덱스는 0부터 시작하기 때문에 경계를 넘은 것이다. 그렇다면 배열에 속하는 인덱스로 고쳐보자.
x[9] = 0;위의 코드로 변경한 후 컴파일하여 valgrind로 확인해보자. 그렇게 되면 에러 메시지가 사라진 것을 확인할 수 있다.
이 프로그램은 앞으로도 유용할 것이다. 우리는 계속해서 메모리를 조작하는 프로그램을 작성할 것이기 때문이다. 우리의 프로그램이 갑자기 죽거나, 멈추거나, 세그멘테이션 오류 같은 것이 일어날 때 말이다.
생각해보기
제한된 메모리를 가지고 프로그래밍을 할 때 메모리를 해제하지 않으면 어떤 문제가 발생할 수 있을까요?
메모리를 많이 할당하지만 해제하지 않으면 프로그램과 컴퓨터의 메모리가 바닥나게 되어 속도가 점점 느려지면서 메모리가 부족하게 되어 에러 메시지를 띄우게 된다.
7. 메모리 교환, 스택, 힙
들어가기 전에
각각 사이다와 콜라가 들어있는 컵 두 개를 떠올려봅시다. 만약 사이다와 콜라를 각각 다른 컵으로 바꿔 담고 싶으면 어떻게 해야 할까요? 교환을 도와줄 수 있는 새로운 컵이 잠시 필요하겠죠. 그렇다면 메모리에 저장된 값들을 교환할 때도 이와 비슷하게 할 수 있을까요?
학습 목표
메모리에 저장된 두 값을 교환하는 코드를 작성할 수 있습니다.
핵심 단어
- 스택
- 힙
- 포인터
학습하기
지금까지 도구를 배웠으니 이제 적용 사례로 넘어가 보자.
지난주에 swap함수가 꽤 유용했던 기억이 나는가? 버블 정렬이나 선택 정렬에서 값을 교환하며 올바른 위치에 뒀었다. 꽤 간단하다. "임시 공간"이 있다면 실제로 따라 해볼 수 있다.
2개의 변수를 교환하기 위해 swap이라는 함수를 작성할 텐데 정수 두 개인 a와 b를 인자로 받아서 바꾸는게 목적이다. b가 a가 되고, a가 b가 되기 위해선 임시 공간이 코드에 필요하다.
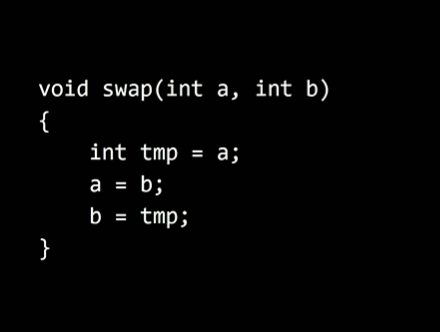
함수를 코드로 나타내면 위와 같다. 임시 공간으로 쓸 변수 tmp에 a를 저장한다. 그리고 a를 b의 값으로 바꾼다. 이미 a를 tmp에 복사해 놓았기 때문에 괜찮다. 그리고 마지막으로 b에다가 tmp에 있는 값을 복사한다.
안타깝게도 이렇게 쉽게 동작하지는 않는다.
//Fails to swap two integers
#include <stdio.h>
void swap(int a, int b);
int main(void){
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(x, y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}실제로 위 코드를 실행해보면 아래와 같이 작동하지 않는 것을 확인할 수 있다.

즉, 제대로 교환되지 않았다. 하지만 코드를 보면 맞는 것도 같다. 컴파일 에러도 없었다. 하지만 swap을 호출해도 값은 전혀 바뀌지 않았다. 어떤 이유일까?
함수에 인자를 전달할 떄 그 값을 복사해서 전닭한다. 따라서 x와 y가 1과 2로 초기화되어 있고, 함수에 인자를 전달하지만 함수는 x과 y 자체가 아니라 x와 y의 복사본을 전달받는다. 그리고 함수의 프로토타입에서 이 두 값을 a와 b라고 부른다.
사실 swap함수는 제대로 동작한다. a와 b를 교환한다. 하지만 x와 y를 바꾸진 않는다. 복사본을 바꾸니까.
이건 심각한 문제다. 버블 정렬이나 선택 정렬에서 필요한 교환 함수를 구현하지 못하니까. 투표 알고리즘을 짤 때 이 문제를 경험했을 수도 있다. 교환하기 위해 도우미 함수를 만들 때 조금 다른 방법을 썼을 수도 있다.
이 현상을 어떻게 설명할 수 있을까?

이 swap함수는 작동하지 않는다. 기본적인 개념으로 돌아가서 컴퓨터 메모리 속을 살펴보자. 그리고 메모리를 격자로 놓인 바이트로 생각해보자.

무슨 일이 일어나는가? 알고 보니 c를 사용할 때 컴퓨터는 메모리 속에서 아무 공간이나 사용하는 게 아니었다. 사실 아주 조직적인 방법으로 사용한다. 특정 자료형을 a로, 다른 자료형은 b로 간다. 이 방식은 뭘까?
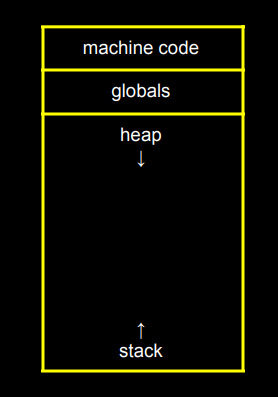
추상적으로 커다란 네모를 보자. 만일 이게 컴퓨터 메모리라면, 가장 맨 위에는 clang이 컴파일한 0과 1의 값이 들어간다. 즉, 머신 코드가 메모리에 올라가는데 ./이름을 치거나 아이콘을 더블 클릭하면 0과 1로 컴파일 된 코드가 메모리 위쪽에 저장된다. 위와 같은 크기를 차지할 수도 있고, 더 큰 공간을 차지할 수도 있다.
그 아래에는 프로그램이 전역 변수나 정보를 쓴다면 컴퓨터 메모리 속 머신 코드 바로 아래 공간에 놓이게 된다. 사람들이 컴파일러를 만들 때 메모리 어디에 둘지 이렇게 정한 것이다.
힙
그 아래는 "힙"이라는 특별한 메모리 영역이 있다. valgrind에서 조금 전에 봤었다.
힙은 우리가 메모리를 할당 받을 수 있는 커다란 영역이다. malloc을 호출하면 메모리를 이 영역에서 가져온다. 전역 변수와 머신 코드 아래이다. clang과 다른 컴파일러 개발자가 그렇게 메모리를 구성하기로 한 것이다. malloc을 호출할 때마다 이 영역에서 가져다 쓴다.
힙은 아래로 자라기 때문에 메모리를 더 사용할수록 점점 더 아래로 내려간다.
스택
하지만 여기 아래에 또 다른 용도로 할당된 메모리 영역이 있다. 프로그램에서 어떤 함수를 호출할 때마다 함수의 지역 변수들은 "스택"이라는 메모리 제일 아래 영역에 놓이게 된다. 기본 함수 main에서 한 개 이상의 인자와 지역 변수가 있다면 이 변수들은 여기 메모리의 아래쪽에 놓인다. swap 같은 다른 함수를 호출하면 그 위에 있는 메모리를 사용한다.
즉, 힙은 malloc이 메모리를 할당하는 곳이고, 스택은 함수가 호출될 때 지역 변수가 쌓이는 공간이다.
실제 동작을 살펴보자.
스택만 생각해보면 변수를 교환할 때 swap 함수의 코드는 어떻게 동작할까?

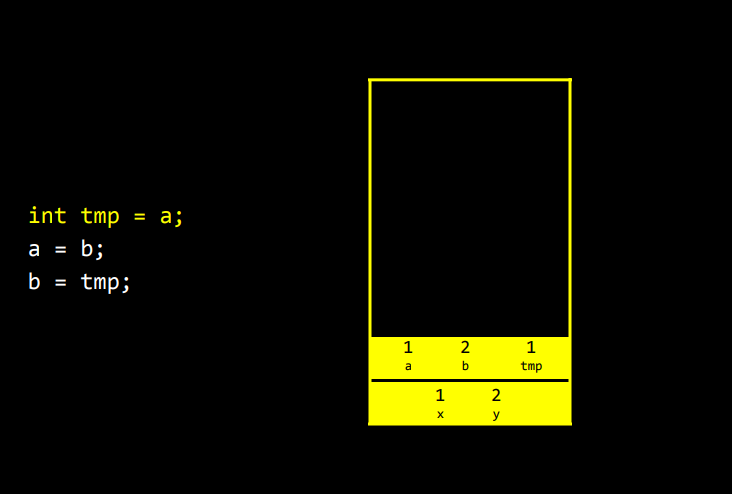
main을 호출하면 메모리 맨 아래에 C프로그램의 기본 작동 방식으로 스택 프레임이라는 공간이 주어진다. argv나 argc 그리고 x와 y같은 지역 변수를 저장하는 공간이다. main 함수 안에 있는 변수는 모두 이 메모리 영역에 저장된다.

main 함수가 swap 같은 함수를 호출하면, 해당함수를 위한 메모리 영역이 main 위에 쌓인다. swap 함수는 a, b, tmp 세 변수가 있었다. 이 세 변수가 이 메모리 프레임에 존재한다. x와 y가 바닥에 놓이고, 그 위에 a, b, tmp가 쌓인다.
다시 이 부분에 집중해보자.

프로그램이 시작하고 main이 호출되면 x와 y 두 변수가 있고, 이를 각각 1과 2로 초기화한다.

그리고 swap 함수를 호출하면, 컴퓨터가 스택에 또 다른 프레임을 위한 영역을 할당해준다.

swap은 a, b, tmp 세 변수가 있었다. 처음 두 개는 인자고, 세 번째는 임시변수이다.
이전에 작성한 코드에서는 a와 b를 1과 2로 초기화했다. 그리고 그 값은 x와 y와 동일하지만 복사본이다.
이제 코드에서 뭘 할까? tmp에 a를 넣으니까 tmp에 1이 들어간다.
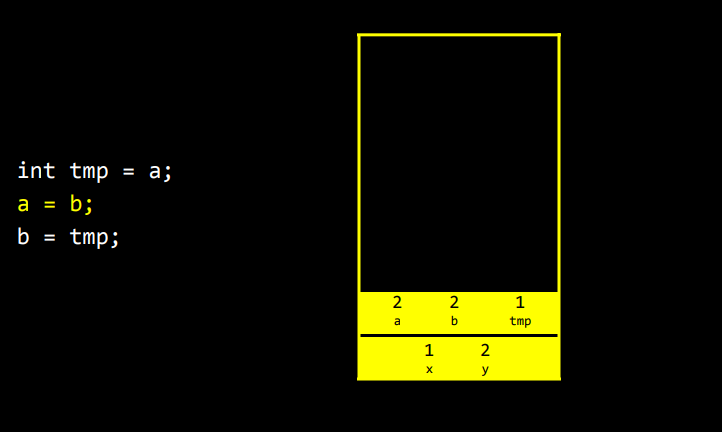
그리고 두 번째 줄에서 a에 b를 넣는다. a에는 b의 값은 2가 들어간다.

b에 tmp를 넣는데 tmp에는 1이 있었다. 성공적으로 교환을 했다. 이 세줄의 코드로 a와 b를 교환했다.

하지만 스택은 식당과 같다. 식당에서 식판이 쌓여있는데, 새로운 식판을 계속 위에 쌓고 맨 위부터 꺼내는 것이다. 교환이 세 번째 줄에서 완료되면, 누가 식판을 꺼내듯 프레임은 사라진다. 물론 메모리가 사라지는 것은 아니다. 물리적인 장치니까. 하지만 이 프로그램을 위해 더 이상 사용되지 않는 것이다.
교환 이후에도 main 함수는 아직 있다. 하지만 x와 y는 전혀 영향받지 않았다. 근본적인 해결책은 뭘까? 복사된 값을 사용하기 때문에 교환되지 않는다. 값을 전달했다. main에서 swap을 호출하면 x와 y가 아니라 a와 b라는 복사본을 전달한다. 어떻게 하면 될까?
참조로 전달한다. 참조는 포인터와 동일한 의미이다. 우편함의 주소로 찾아가 값을 살펴보듯, main에서 x와 y의 값을 swap에게 전달하지 않고 x와 y의 주소를 알려줘서 swap함수가 그 주소로 가서 값을 바꾸게 하는 것이다. 그럼 함수가 끝나도 제대로 바뀌어 있다.
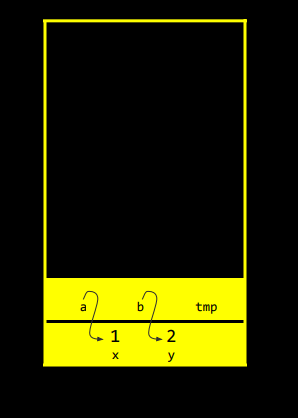
그림으로 보면 이거다. 다시 시도해볼건데, main 함수에서 x와 y를 1과 2로 초기화하고, swap을 호출한다. 이번에는 이 그림에 보이듯 a가 x를 가리키고, b가 y를 가리키게 할 것이다. x와 y의 값이 같게 만들지 않는다. 그럼 이제는 빵가루처럼 이 경로를 따라가서 a에서 x로, b에서 y로 갈 수 있으니 값을 교환한다.
#include <stdio.h>
void swap(int *a, int *b);
int main(void){
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *x, int *y){
int tmp = *x;
*x = *y;
*y = tmp;
}*를 여기저기 붙였다. 이전 코드와 다른 점은, 13번 줄에서 x와 y를 전달하지 않고 x와 y의 주소를 전달한다.
swap(&x, &y);오늘 수업에서 배웠던 &의 역할이다. x의 주소와 y의 주소를 의미한다. 지도를 줘서 swap 함수가 찾아갈 수 있게 하는 것이다.
인자로 어떤 주소를 받는 함수를 정의하는 swap함수 안이 조금 복잡해 보일 수도 있다.
void swap(int *x, int *y){그러나 함수의 이름이 있고, 포인터 형과 포인터 형이다. int *a는 정수의 주소를 받아 a라 부른다는 의미이다. 또 다른 정수를 받아 b라고 부른다.*표시의 의미를 알아봤다. a와 b모두 정수를 가리키는 포인터이다.
int tmp = *x;
*x = *y;
*y = tmp;그리고 함수 내용이 조금 어려워 보이지만 이도 비슷한 내용이다. *a가 뭘까? *는 그 주소로 가라는 것이다. 따라서 *a는 a가 가리키는 곳으로 따라가라는 것이다. 그게 어디였나? x를 가리켰다. 그럼 a가 가리키는 주소로 가면 x가 있고 1이라는 값이 있다. 그 값을 tmp에 저장한다.
그다음 b로 가라한다. b의 주소를 따라가면 y에 도착한다. 그리고 y는 2였다. *a의 의미는 a가 가리키는 주소로 가서 b가 가리키는 값을 저장하라는 것이다. 마지막으로 tmp의 값인 1을 b가 가리키는 주소에 저장한다.
코드로 어려우니 그려보자. 위의 세 줄은 이제 그림으로도 동작하게 된다.

첫 줄은 a에 있는 값을 tmp에 저장하라는 것이다. 이제 a의 화살표를 따라 x로 가보자. 1이 나온다. 그리고 1을 tmp에 저장한다.

그다음은 b속 주소로 가보자. 화살표를 따라가면 2가 나온다. 이제 a 속 주소를 따라서 x에 2를 저장한다.

마지막 줄은 b속 주소로 가서 그곳에 tmp를 저장한다. 화살표를 따라 b속 주소로 가서 tmp로 바꾼다.
여전히 swap함수를 호출하고 여전히 지역변수를 사용하지만 이 지역 변수는 보물 지도 같은 포인터이기 때문에 그 화살표를 따라가보면 메모리 속 값을 찾을 수 있다. swap 함수가 반환해서 a와 b, tmp가 사라져도 괜찮다. 왜냐하면 x와 y자체의 값을 교환했기 때문이다.
Q.주소를 해제하지 않아도 되나요?
위 코드에서는 malloc을 사용하지 않기 떄문에 해제할 게 없다. malloc없이도 주소를 사용할 수 있다. 이 경우에는 &연산자를 사용하여 x와 y의 주소를 알아냈다.
Q. 함수속에서 malloc을 사용하며 메모리 영역을 할당해줄 텐데 그걸 어떻게 다룰까요?
책임은 우리에게 있다. 어떻게든 그 메모리 영역을 기억해서 해제해야만 한다.
get_string가 이렇게 한다. 짧게 알려주자면 get_string은 malloc으로 메모리를 할당한다. 지금까지 우리가 문자열 메모리를 해제한 적이 없지만, cs50 라이브러리의 쓰레기 수집이라는 기능이 프로그램이 종료될 때 해제되지 않은 메모리르 ㄹ해제해준다. cs50 라이브러리를 살펴보면 어떻게 되는지 알 수 있다.
생각해보기
메모리 영역을 다양하게 나누는 이유는 무엇일까요?
사용에 따라 각 메모리 영역을 다양하게 나누게 되면 메모리를 효율적으로 사용할 수 있다.
만약 나누지 않고 메모리를 사용한다면 메모리를 할당하고 해제하게 되었을 때 메모리에 남는 구역이 많이 생기게 된다. 따라서 메모리가 연속적이지 않고 비연속적인 형태를 띄게 되므로 결론적으로 메모리를 낭비하게 된다.
8. 파일 쓰기
들어가기 전에
get_int나 get_string처럼 사용자에게 입력을 받는 함수는 어떻게 구현되어 있었을까요? 앞서 배운 메모리 교환, 스택의 정의를 잘 복습한 후에 두 함수를 직접 구현해보고, 더 나아가서 파일에 출력해보는 방법도 알아 보겠습니다.
학습 목표
사용자로부터 값을 입력받아 파일에 출력하는 프로그램을 작성할 수 있습니다.
핵심 단어
- scanf
- fopen
- fprintf
- fclose
학습하기

사실 저번 시간에 배운 이 메모리 설계가, 가장 좋은 설계는 아니다.
버퍼 오버플로우(buffer overflow)

위 그림을 보면 어떤 생각이 드는가? 서로 부딪칠 것이다. 계속 malloc을 호출하면 화살표 방향으로 메모리를 계속 사용하게 된다. 하지만 스택도 커질 수 있다. 함수를 계속해서 호출하게 되면 두 메모리 영역이 어디선가 충돌할 것이다.
스택 오버플로우 (stack overflow)
지난주에 배운 재귀를 기억하는가? 시작점 없이 자기 자신을 계속 호출하면 스택 오버플로우를 겪을 것이다. 프로그래머에게 유명한 사이트인 스택 오버플로우가 여기서 유래됐다. 자기 자신을 계속 호출하는 버그가 있는 프로그램을 실행하면 스택이 넘칠 수 있다. 다른 이유도 있지만, 사이트 이름의 근원은 이것이다.
힙 오버플로우 (heap overflow)
힙 오버플로우는 반대로 malloc을 계속 호출해 너무 많은 메모리를 할당하여 메모리 속 다른 내용을 덮어쓰게 된다.
안타깝게도 제한된 크기의 메모리에서는 어쩔 수가 없다. 그러므로 컴퓨터가 넘 많이 메모리를 쓰다 보면 파일이나 사진이 열리지 않거나 아니면 화면이 정지하거나 아예 동작하지 않는 상황이 생기는 것이다. 이 현상을 "버퍼 오버플로우"라고 한다.
사용자에게 입력받기
이제 마지막 보조 바퀴를 떼보자. 아까 질문한 여기 모든 함수는 get_float, get_string, get_double 등등 CS50 라이브러리에 있는 함수들은 포인터를 사용한다. 메모리 주소를 잘 관리해서 우리가 신경 쓸 필요가 없었다.
이제 get_int를 구현해보자. CS50라이브러리 없이 똑같은 역할을 하게 될 것이다.
scanf라는 프로그램을 만들겠다. 형식이 있는 scan을 의미한다. 다음 기능을 구현해보자.
#include <stdio.h>
int main(void){
int x;
printf("x: ");
scanf("%i", &x);
printf("x: %i\n", x);
}이전에는 get_int로 정수로 입력받았지만 이제 CS50 라이브러리를 제거했으니 대안이 필요하다. 사실 scanf라는 함수가 있는데 이 함수는 printf와 비슷하다.
scanf("%i", &x);""속에 형식 지정자를 쓰면 그 형식대로 입력을 받는다. 그리고 콤마(,)후에는 사용자의 입력을 저장하고 싶은 변수의 주소를 적는다.
scanf는 깜빡이는 입력창을 띄워 사용자가 숫자를 입력하고 엔터를 누르면 그 숫자를 저 주소에 저장한다. scanf와 같은 함수를 부를 때 x의 주소를 scanf에게 주는 이유는 swap함수와 같다. 도우미 함수 또는 남이 작성한 코드로 변수의 값을 바꾸고 싶다면 값으로 전달하면 안된다. 그럼 복사본을 전달하고 결국 사라진다. 대신에 &x 를 사용해서 주소를 전달해야 한다. 그래야 swap이나 scanf같은 함수가 그 주소를 찾아가 값을 저장할 수 있다.
안타깝게도 scanf에 사용자가 정수 대신에 emma를 적는다면 프로그램이 죽거나 예상치 못한 방식으로 흘러간다. scanf에는 에러 확인 기능이 없다.
다른 걸 해보자. 정수형을 읽는 것은 재미없으니 문자열을 받아보자.
#include <stdio.h>
int main(void){
char *s;
printf("s: ");
scanf("%s", s);
printf("s: %s\n, s");
}5번 줄에서 변수 s를 선언한다. 그곳에 문자열의 주소를 저장할 것이다.
scanf는 형식 지정자를 받아 사용자로부터 무엇을 입력받을지 파악하고 저장할 주소를 받는다. char *는 주소이기 때문에 &가 필요없다. 포인터 변수는 그 자체가 주소로 정의된다.
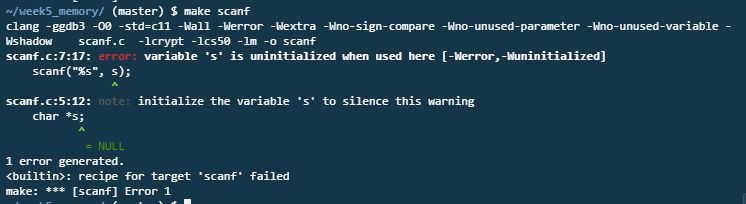
그렇다면 위 코드를 컴파일하고 실행해보자. 에러가 난다. 변수 s를 초기화하지 않고 사용했기 때문이다.
s를 주소로 초기화 시켜줘야 한다. emma의 이름을 어디에 둘까? 0x123 같은 주소에 둘까? 주소를 미리 알 수 없으니 "NULL"이라고 쓰자. 빈 공간을 의미한다. NULL은 특별한 포인터로 가리키는 곳이 없다는 뜻이다. 모두 0이다.
다시 컴파일 후 실행해보자. 하지만 아래와 같은 결과가 뜬다.

왜 글자가 저장되지 않을까? 왜 동작하지 않을까?
char *s의 의미를 기억하는가? 메모리 영역의 주소를 저장할 수 있는 변수를 말한다. NULL은 메모리 공간이 할당되지 않았다는 뜻이다. 엄밀히 말해 EMMA의 이름이 저장될 공간을 할당하지 않았다. 따라서 우리가 해야할 것은 사용자가 EMMA를 입력한다고 가정하고 크기 5의 문자 배열을 선언하자. 그리고 scanf에 주소를 건네주자.
char s[5];요약해보면, 오늘 배운 내용을 보면 배열과 포인터는 사실 연관되어 있다. 배열은 메모리가 연속적으로 할당된 공간이다. 문자열은 문자가 연속적으로 있는 것이다. 문자열은 사실 그 메모리 공간 첫 번재 주소를 의미한다. 따라서 추이적 관계에 의해 최소한 이 문맥에서 포인터는 배열과 같다고 볼 수 있다.
이제 크기 5의 문자 배열을 선언할 텐데, 사실 clang컴파일러는 문자 배열의 이름을 포인터처럼 다룬다. scanf의 상황에서는 배열 첫 바이트 주소를 남겨주는 것이다.
#include <stdio.h>
int main(void){
char s[5];
printf("s: ");
scanf("%s", s);
printf("s: %s\n", s);
}이제 세 번째 버전을 실행해보면, 다음과 같이 이제 emma 문자가 저장되는 것을 확인할 수 있다.

하지만 욕심을 부려서 emma 글자보다 더 길게 적게 되면, 4글자 이상 저장되지 않는다. 왜냐하면 충분한 공간을 할당하지 않았기 때문이다. 하지만 다행히 프로그램이 멈추지 않았다. 그렇지만 커다란 문단을 입력하다면 프로그램이 분명 멈추거나 세그멘테이션 오류가 발생할 것이다. 앞으로 메모리를 다루면서 이 오류 메시지를 자주 볼 것이다.
파일쓰기
마지막 예제를 보자.
이제 우리는 메모리 주소를 다룰 수 있게 되었응니, 지난주에 봤던 phonebook.c 프로그램에 최초로 파일의 정보를 저장해볼 것이다. 잠시 cs50 보조 바퀴를 가져와 사용자의 입력을 쉽게 받겠다.
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void){
FILE *file = fopen("phonebook.csv","a");
}file이라는 파일을 만들고, fopen이라는 함수를 사용해서 phonebook.csv를 연다.
어떻게 됐나? 앞으로 우리는 포인터와 점점 더 익숙해질 것인데, 여기 모두 대문자로 쓰인 FILE이라는 새로운 자료형을 가리키는 포인터 변수 file을 만들 수 있다. 즉 file은 변수의 이름이고, 오늘 우리의 파일 내용을 저장해줄 것이다. 엄밀히 말하면 아니지만 임시로 그렇다고 하자.
fopen은 첫 번째 인자로 열고 싶은 파일 이름을, 두 번째 인자로는 r, w, 혹은 a를 받는다. r은 읽기, w는 쓰기, a는 덧붙이기이다. 파일을 계속 추가하는 것이다.
우리의 목표는 전화번호부를 만들어 사용자로부터 이름과 번호를 받아 텍스트 파일에 덧붙이는 것이다. 데이터베이스처럼 사람들의 전화번호를 추적할 수 있도록 말이다.
fopen은 해당 파일을 가리키는 포인터를 반환한다. 이제 다음처럼 해보겠다.
char * name = get_string("Name: ");
char *number = gete_string("Number: ");scanf를 사용해도 되지만, 그렇게 되면 신경써야할 오류가 많아지므로 편의를 위해 우선은 get_string을 사용하겠다.
fprintf
printf와 별개로 fprintf라는 함수가 있다. 파일용 printf로 파일에 출력할 수 있다. 이제 파일을 출력해보자.
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void){
//Open file
FILE *file = fopne("phonebook.csv","a");
//Get strings from user
char * name = get_string("Name: ");
char *number = gete_string("Number: ");
//Print (write) strings to file
fprintf(file, "%s, %s\n", name, number);
//Close file
fclose(file);
}csv가 뭔지 아나요? 쉼표로 분리된 값이다. 간단한 엑셀이나 Numbers같은 프로그램으로도 열 수 있다.
나만의 csv 파일을 만들어보겠다. phonebook을 컴파일하고 실행해보자.
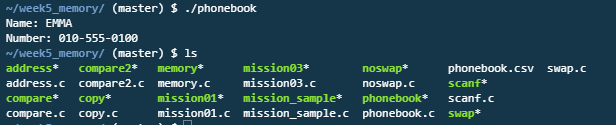
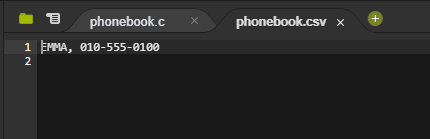
phonebook.csv 파일이 생겼다. 그리고 이 파일을 열어보면 아래와 같이 파일에 EMMA의 이름과 번호가 있는 것을 확인할 수 있다.
프로그램을 한 번 더 돌려보자.
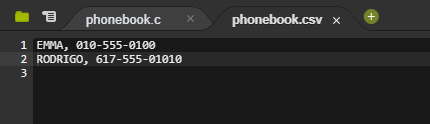
짜잔! 또 추가되는 것을 확인할 수 있다. csv 파일이 실시간으로 업데이트 된다.
이제 IDE로부터 파일을 받아보자. 오른쪽 클릭하여 다운로드하면 Numbers나 엑셀 같은 프로그램으로 이름과 번호가 저장된 스프레드스트를 볼 수 있다.

정보 과학에서처럼 데이터 분석을 할 때, 우리가 익숙한 행렬 형태의 csv파일로 데이터를 생성해주는 코드를 작성할 수 있다.
9. 파일 읽기
들어가기 전에
우리가 일상적으로 사용하는 파일은 텍스트, 이미지, 영상 등 여러 형식이 있습니다. JPEG 형식의 파일인 경우 그 값 속에는 JPEG파일 형식인지를 알려주는 실마리가 있습니다. 이번 강의에서는 JPEG 파일을 읽고 그 실마리를 찾아보도록 하겠습니다.
학습 목표
파일을 읽고 JPEG 파일인지를 검사하는 프로그램을 작성할 수 있습니다.
핵심 단어
- JPEG
- fread
학습하기
이제 마지막 예제를 살펴보자.
우리 앞에 JPEG 형식으로 된 Brian 사진이 있다. 또 GIF형식으로 된 고양이 사진도 있다. 각각 GIF와 JPEG 형식으로 이미 익숙한 이미지 파일 형식이다.
jpeg.c 라는 프로그램을 만들어 보자. 목표는 명령줄로 주어진 파일이 JPEG인지 아닌지 확인해주는 것이다.
#include <stdio.h>
int main(int argc, char *argv[]){
// Ensure user ran program with two words at prompt
if(argc != 2){ //입력한 파일이 없으면 프로그램 종료.
return 1;
}
// Open file
FILE *file = fopen(argv[1], "r");
if (file == NULL){
return 1;
}
// Read 3 bytes from file
unsigned char bytes[3];
fread(bytes, 3, 1, file); //배열, 읽을 바이트 수, 읽을 횟수, 읽을 파일
//즉, 파일에서 3바이트를 읽어옴
//,Check if bytes are 0xff, 0xd8, 0xff -> jpeg file
if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff){
printf("Maybe\n");
}else{
printf("No\n");
}
}malloc, fopen, get_string과 같은 함수는 에러가 생기면 NULL이란 값을 돌려준다. 따라서 여기서 문제가 생기면 1을 반환해준다.
크기가 3인 bytes배열을 만들어 준 이유는 아래 코드에서 볼 수 있다. 우선, fread 함수를 이용해서 파일에서 3bytes를 읽어온다. 모든 jpeg파일은 첫 세 바이트는 무조건 ff, d8, ff로 시작한다. jpeg 개발자들이 정한 일종의 매직 넘버로, 파일의 시작점에서 파일이 jpeg 사진이라는 것을 알려주기 위한 것이다. 따라서 if문과 같이 각 바이트들이 jpeg 파일의 형식과 같은지 확인한다. 이 조건을 만족한다면 maybe이지만, 만족하지 않는다면 확신을 가지고 No이다.
그리고 bytes는 unsigned형식이다. 이는 -128부터 127이 아닌 0부터 255 범위의 값을 의미한다.
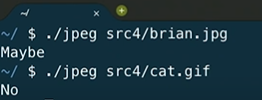
결과는 위와 같이 나온다.
즉 포인터를 배우게 되면 파일에 적을 뿐만 아니라 읽을 수도 있다. 이 정보를 어디에 쓸까?
우리는 사진 파일이 어떻게 생겼는지 첫 주에 이야기를 했었다.
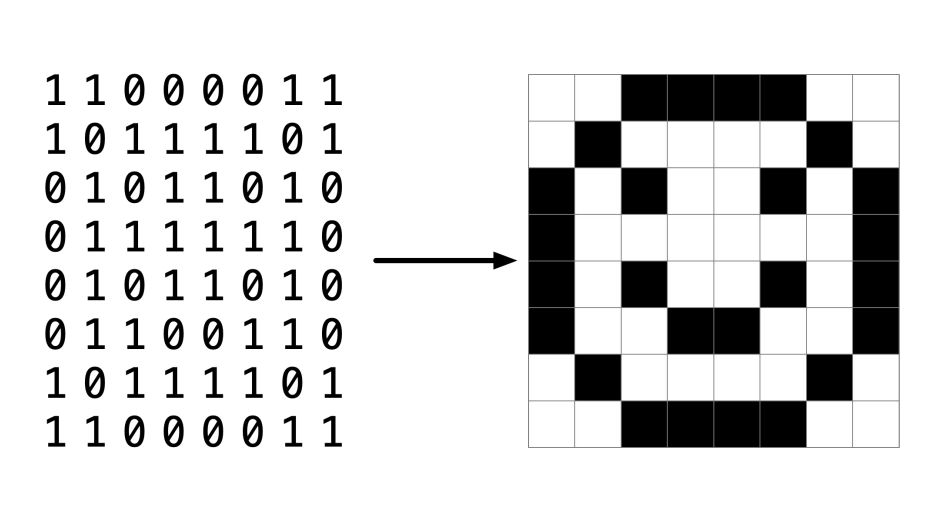
이것은 이미지다. 하지만 이진수로 되어있다. 1은 흰색, 0은 검은색을 나타난다고 생각하면 0과 1이 격자로 되어 있으니 멀리서 보면 웃는 얼굴이 보인다. 이렇게 사진 또는 비트맵이 이미지의 픽셀을 나타낸다.
생각해보기
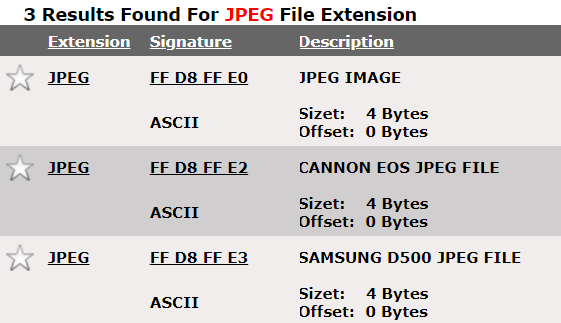
JPEG 외에 다른 파일 형식도 그 형식임을 알려주는 약속이 있을까요?
네, 있습니다. "파일 매직 넘버" 또는 "파일 시그너처"로 불리며, 아래 사이트를 통해 '약속'된 것을 확인 할 수 있습니다.
파일 매직 넘버 참고 사이트:
1. https://www.garykessler.net/library/file_sigs.html
2. https://www.filesignatures.net/index.php?page=all
'Education' 카테고리의 다른 글
| [부스트 코딩 뉴비 챌린지 2020] week5_샘플미션 (0) | 2020.08.07 |
|---|---|
| [부스트 코딩 뉴비 챌린지 2020] week4_코벤져스 LIVE 강의 (0) | 2020.08.07 |
| [부스트 코딩 뉴비 챌린지 2020] week4_미션03 (0) | 2020.08.07 |
| [부스트 코딩 뉴비 챌린지 2020] week3_미션03 (0) | 2020.08.06 |
| "cat [파일명]": 파일 내용 확인하기 (0) | 2020.08.06 |
