1. malloc과 포인터 복습
들어가기 전에
이번 강의부터는 C로 구현할 수 있는 다양한 데이터 구조를 배우게 됩니다. 데이터 구조를 정의하고 관리하는데 있어서 메모리와 포인터에 대한 개념을 정확히 이해하는 것이 중요합니다. 먼저 지난 시간에 배운 malloc 함수와 포인터를 복습할 수 있는 작은 예제를 살펴 보겠습니다.
학습 목표
포인터의 개념과 malloc 함수의 용법을 잘 이해할 수 있습니다.
핵심 단어
- 포인터
- malloc
학습하기
지난 강의에서 우리는 몇 개의 새로운 c문법을 배웠다. 포인터로 메모리상의 실제 주소를 확인할 수도 있었고, * 연산자나 malloc과 free같은 함수로 메모리를 관리하는 방법에 대해서도 배웠다.
복습으로 다음과 같이 버그가 있는 짧은 코드를 보자.
int main(void){
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
*y = 13;
}한 줄 씩 보자.
첫 번째 줄은 정수를 가리키는 포인터를 만들고 그 변수를 x라고 부른다. 다음 줄 역시 정수를 가리키는 변수 y를 만든다.
세 번째 줄은 int 크기의 메모리를 만들어 x에 할당해준다. malloc은 할당받고 싶은 크기의 유일한 인자를 받아 메모리를 할당해준다. 정수형의 크기를 잊었어도 sizeof 연산자를 사용하면 대부분 4를 반환한다. 따라서 이 코드는 컴퓨터에게 4 바이트의 공간을 요청한다. 그러면 메모리 덩어리를 할당하고 메모리 영역의 첫 주소를 반환해준다. 0x로 시작하는 4 바이트가 있는 주소이며, 그 주소를 x에 저장한다. x는 포인터 변수이기 때문에 주소를 저장해도 된다. 즉 변수x를 선언하고 그 안에 메모리의 주소를 저장한다.
하지만 보통 정수를 이렇게 할당하지 않는다. 정수는 int n;으로 만든다. 하지만 이제 주소와 메모리를 할당할 수 있기 때문에 적용해보았다.
네 번째 줄은 x에 저장된 주소로 가서 42를 저장한다. *은 역참조 연산자이다. 그 주소로 가라는 말이다. 대입 연산자를 사용해서 42를 그곳에 저장한다. malloc이 할당해준 4byte 크기의 메모리에 가서 42를 넣으라고 한다. 적절히 0과 1을 섞어서 말이다.
마지막 줄에 버그가 있다. 아직 해당 변수를 위한 공간을 할당하지 않았다. 위에 int *y;라고만 썼으니 쓰레기 값이 있다고 가정해야 한다. 프로그램 다른 부분의 흔적일 수도 있다. 프로그램의 시작에서는 아닐 수도 있지만 안전을 생각해서 초기화하지 않은 변수에는 뭐가 있는지 모른다. 가짜 주소가 있어서 *y로 그 가짜 주소를 찾아가 보면 코드의 메모리 문제나 세그멘테이션 오류 같은 안 좋은 일들이 발생한다. 없거나 잘못된 주소에 접근하면 말이다.
초기화하지 않은 *y는 프로그램 어딘가를 임의로 가리키고 있을지도 모른다. 따라서 그 곳에 13이라는 값을 저장하는 것이 오류를 발생시킨다.
그럼 마지막 줄을 개선해보자.
int main(void){
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
y = x;
*y = 13;
}y = x; 라고 작성하게 되면, y는 x가 가리키는 곳과 동일한 주소를 가리키게 된다. x안에 있는 주소를 y에도 저장하고, 그 주소로 가서 13을 저장하라고 한다. 하지만 그럼 42는 없어지고 13으로 덮어져 버린다. x와 y가 같은 주소를 가리키기 때문이다.
간단히 말해 할당하지 않은 메모리를 사용하면 안 좋은 일이 벌어질 수 있다.
같은 이야기지만 기억하는데 도움이 되는 스탠포드에서 만든 아래 짧은 영상을 보자.
포인터는 처음에는 아무것도 가리키지 않는다. 포인터가 가리키는 것을 포인티라고 하는데, 그건 별도로 설정해야 한다. 포인티는 malloc을 이용해서 포인티를 할당할 수 있다.
생각해보기
포인터를 초기화시키지 않고 값을 저장하면 어떤 오류가 발생할 수 있을까요?
초기화시키지 않음은 즉 포인터가 가리키고 있는 곳이 존재하지 않는다(=가리키는 메모리 주소를 지정하지 않음는 뜻이다. 메모리를 지정해 가리키고 있는 곳이 없이 특정 값을 넣게되면, 그 특정 값이 어디에도 위치하지 않은 쓰레기 값으로 메모리상에 존재하게 된다.
이로 인해 없거나 잘못된 주소에 접근했을 때 발생하는 코드의 메모리 문제나 세그멘테이션 오류가 생긴다.
2. 배열의 크기 조정하기
들어가기 전에
컴퓨터 안의 메모리는 마치 사물함과 같은 구조입니다. 우리가 사용하고자 하는 사물함의 개수를 한 번 정한 이후에는, 공간이 모자란다고 해서 주변의 사물함을 마음대로 더 사용할 수는 없습니다. 이미 다른 목적으로 사용되고 있을 수도 있기 때문이죠. 이와 같이 이미 일정한 크기의 메모리가 할당되어 있는 상황에서, 그 크기를 늘리는 일은 생각만큼 단순하지는 않습니다. 이번 강의에서는 포인터와 malloc의 개념을 응용해서, 이미 정의된 배열의 크기를 바꿔보도록 하겠습니다.
학습 목표
배열의 크기를 조정하는 코드를 작성할 수 있습니다.
핵심 단어
- malloc
- realloc
학습하기
2주차에서 우리는 배열에 대해서 배웠고, 이는 우리가 배운 첫 번째 자료구조였을 것이다. 그보다 전인 1주차에서는 정수나 문자나 실수를 담을 수 있는 변수만 알고 있었다. 2주차에서는 배열을 배웠고, 우리는 이제 정수를 한꺼번에 저장할 수 있다.많은 데이터를 한번에 캡슐화 할 수 있는 것이다.

하지만 배열은 생각만큼 강력하지 않다. 예로 들어 크기가 3인 배열을 가지고 세 개의 값을 저장했는데 네 번째 값도 저장하려는 상황을 가정해보자. 하지만 처음에는 이런 상황을 예상하지 못했다. 배열의 크기는 미리 지정해야 한다고 앞에서 배웠다. 그래서 3이나 3이 포함된 변수를 하드코딩해야 한다. 하지만 네 번째 숫자를 저장하려고 할 때 우리는 아마도 새로운 메모리 박스를 하나 더 가져와서 3 옆에 두고 모든 숫자들을 한 번에 저장하면 된다고 생각할 것이다. 하지만 지난주까지 배운 내용으로는 좋은 생각이 아니다. 왜냐하면 컴퓨터의 나머지 메모리의 관점에서는 이 숫자 1, 2, 3은 다른 바이트로 둘러싸여 있기 때문이다. 지난 주에 배웠듯, 이 바이트들은 다른 데이터들로 채워져 있다. 우리 프로그램의 다른 부분에서 쓰이는 데이터이다.

이 그림을 보면 숫자 1, 2, 3이 구석 부분에 있어서 숫자 4를 넣을 공간이 없고, 그래서 배열에 네 번째 숫자를 추가할 방법이 없다고 생각한다. 이를 해결하려면 어떻게 해야할까?
다른 메모리로 이동시키면 된다. 배열의 크기를 바꾸기 위해서 모든 EMMA들을 다 옮기려면 이 문자들을 모두 옮겨야 하기 때문에 시간이 너무 많이 걸린다. 그렇다면 1, 2, 3을 이 아래로 옮기면 4를 넣을 수 있는 공간이 생기지 않을까? 그러므로 배열을 사용하더라도 메모리를 움직이면 이런 결과를 만들 수 있다.

하지만 이 과정에서는 무엇이 포함되는지 보자. 이전 배열이 왼쪽 위에 있고, 크기가 4인 새로운 배열이 오른쪽 아래에 있다. 이제 충분한 공간이 생겼다. 그럼 어떻게 배열의 크기를 늘릴 수 있을까? 이는 일종의 눈속임이다. EMMA들이 주변에 있을 때에는 배열의 크기를 바꿀 수 없다. 대신 이 배열을 움직이거나 복사해오는 것이다.

다음과 같이 숫자 1, 2, 3을 새로운 메모리로 옮겼다. 이렇게 하면 이전에 사용한 메모리를 버리거나 free를 실행하고, 새로운 4를 추가하면 된다.

하지만 이게 최선의 방법은 아닐 것이다. 숫자를 옮기려면 꽤 많은 단계를 거쳐야만 한다. 1를 꺼내서 넣고 2를 꺼내서 또 넣고 3도 꺼내서 또 넣고. 실제로는 할 일이 꽤 많다는 것이다. 아직도 할 일이 남았다. 가서 4를 가져온 다음에 배열에 추가해야만 한다. 즉, 비유적으로 그리고 물리적으로 굉장히 많은 단계를 거쳐서 배열의 크기를 3에서 4로 늘리게 된다.
즉, 이 알고리즘이 얼마나 효율적이거나 비효율적인지 생각하기 위해서, 여기서 어떤 연산과 얼마만큼의 실행 시간이 추가적으로 숫자를 넣어주는데 필요했는지 생각해보자.

배열에 추가될 때의 실행 시간이 어떻게 될까? O(n). 배열에서 몇 개의 숫자를 옮기던지간에 n개가 있다면 이 숫자들을 새로운 배열로 옮겨야 한다. 왔다가 다시 가야하니까 2n만큼 걸린다. 하지만 n의 배수이다. 여기에 부가적으로 숫자 4를 붙이는 부가적인 실행이 추가된다.
그렇기 때문에 이미 만들어진 배열에 실제로 추가하는 데에는 O(n). 즉, 선형 관계만큼의 시간이 든다. 탐색을 할 때에는 강력해지는데, 숫자가 정렬되어 있을 때 탐색을 하면 실행시간은 얼마인가? 2주 전에 배운 바에 따르면 log n이 된다. 이를 놓칠 필요는 없다. 이것이 바로 데이터를 정렬된 배열로 저장할 때의 장점이다.이진 탐색을 사용할 수 있다.
하지만 움직이는 방법은 시간이 많이 들고 이상적인 접근법은 아니다. 이를 코드로 나타내보자.
#include <stdio.h>
int main(void){
int list[3];
list[0] = 1;
list[1] = 2;
list[2] = 3;
for (int i = 0; i < 3; i++){
printf("%i\n", list[i]);
}
}
하지만 이 코드에는 근본적인 문제가 있다. 직접 이 배열의 크기를 타이핑해서 하드코딩했기 때문에 네 번째 숫자를 어떻게 넣을 수 있을까? 무엇을 해야할까?
우리는 지난 주에 메모리를 동적으로 할당할 수 있는 함수를 배웠다. malloc이다. 이를 이용하면 정해진 숫자를 코드에 타이핑 할 필요가 없다. 일정량의 메모리를 동적으로 할당할 수 있게 된다. 이를 이용해 좀더 효과적인 방법으로 확장해보자.
#include <stdio.h>
int main(void){
int *list = malloc(3 * sizeof(int));
list[0] = 1;
list[1] = 2;
list[2] = 3;
for (int i = 0; i < 3; i++){
printf("%i\n", list[i]);
}
}정수 크기의 3배만큼 malloc하면 3개의 정수에 맞는 메모리를 받을 수 있다. 포인터를 반환받고 왼쪽에 있는 포인터에 저장한다.
여기서 C의 멋진 점은, 이제 우리는 list가 메모리 덩어리라는 사실을 알게 되면 2주차에 배운 대괄호 기호를 그대로 사용할 수 있기 때문에 배열을 초기화하는 세 줄은 고칠 필요가 없다. 포인터 이름 옆에 대괄호를 쓰면 컴퓨터는 자동으로 그 메모리 덩어리의 첫 번째 바이트로 이동한다. 모두 malloc이 반환했던 범위 안에 있다. 정수에는 4바이트가 필요하다. 그리고 놀랍게도 대괄호에 0을 적으면 0번 바이트가 나온다. 대괄호에 1을 적으면 두 번째 바이트가 아닌 4바이트 뒤가 된다. 대괄호에 2를 넣으면 세 번째 바이트가 아닌 8바이트 뒤가 된다. 왜냐하면 4 + 4+ 4, 즉 12바이트를 할당받았기 때문이다. 그리고 대괄호는 정확한 메모리 덩어리로 가서 정수 3개를 알맞게 넣을 수 있도록 해준다.
Q. 왜 포인터를 정수 배열이 아니라 정수에 할당하나요?
이 맥락에서는 배열과 포인터는 어떤 의미에서는 동일하다. 포인터는 메모리의 주소이고, 배열은 메모리 덩어리이다. 우리는 메모리 덩어리를 배열이라는 이름으로 사용했었지만, 조금 더 일반적으로 배열은 대괄호를 통해 나타낼 수 있는 메모리 덩어리이다. 하지만 이제 우리는 원하는 만큼의 메모리를 할당할 수 있고, 이 두 가지 개념을 서로 바꿔서 사용할 수 있다.
복잡한 프로그램이 아니더라도 malloc을 사용하면 코드가 루프를 돌며 계속해서 더 많은 메모리를 필요할 때마다 할당하는 예를 상상할 수 있다. malloc이 이를 가능하게 해준다.
여기서 몇 가지 안전성을 점검해봐야 한다.
malloc은 가끔 메모리를 다 쓸 수도 있다. 따라서 메모리가 부족한지 우리는 반환값을 보도록 한다.
if(list == NULL){
return 1;
}메모리가 부족해서 잘못된 경우이다. 따라서 널이 반환되었는지 확인해보는 것이 좋다.
이제 또 다른 정수 값 하나가 필요하다고 해보자. 배열의 크기를 바꾸고 싶은 것이다.
#include <stdio.h>
int main(void){
int *list = malloc(3 * sizeof(int));
if(list == NULL){
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
int *tmp = malloc(4 * sizeof(int));
if ( tmp == NULL){
return 1;
}
for (int i = 0; i < 3; i++){
printf("%i\n", list[i]);
}
}우선 정수형 배열의 크기가 4인 메모리 덩어리 tmp를 만들었다.
컴퓨터의 메모리에서 무언가를 옮기려면 어떻게 했었나? 각각에 접근해서 값을 옛 배열에서 새 배열로 옮겼다.
//Copy integers from old array into new array
for (int i = 0; i < 3; i++){
tmp[i] = list[i];
}여기서 다가 아니다. 3번 위치에도 우리는 저장을 하고 싶다.
tmp[3] = 4;
따라서 위의 네 줄에 의해 우리는 기존의 배열에서 새로운 배열로 옮기는 물리적인 개념을 구현해보았다. 하지만 한 가지가 더 남았다. 메모리 덩어리 사용이 끝나면 free함수를 불러 해제해주어야 한다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
//int 자료형 3개로 이루어진 list 라는 포인터를 선언하고 메모리 할당
int *list = malloc(3 * sizeof(int));
// 포인터가 잘 선언되었는지 확인
if (list == NULL)
{
return 1;
}
// list 배열의 각 인덱스에 값 저장
list[0] = 1;
list[1] = 2;
list[2] = 3;
//int 자료형 4개 크기의 tmp 라는 포인터를 선언하고 메모리 할당
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
// list의 값을 tmp로 복사
for (int i = 0; i < 3; i++)
{
tmp[i] = list[i];
}
// tmp배열의 네 번째 값도 저장
tmp[3] = 4;
// list의 메모리를 초기화
free(list);
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 배열 list의 값 확인
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
// list의 메모리 초기화
free(list);
}
이렇게 결과도 잘 출력되는 것을 확인할 수 있다.
하지만 이 프로그램은 약간 바보 같다. 만약에 이 프로그램을 반쯤 짜다가 세 개가 아닌 네 개의 정수가 저장하고 싶어지면 그냥 이전 코드를 삭제하고 다시 짜면 되기 때문이다. 이게 더 커다란 프로그램이었다면 어떤 사람이 정수를 새로 받아와서 메모리가 더 필요해지면 이런 방식으로 malloc을 사용하면 된다는 시범이었다.
realloc()
여기서 이 과정을 조금 더 간단하게 해주는 함수가 있다. 직접 메모리를 할당하거나 직접 값들을 옮기고 free를 할 필요가 없어진다. 이 많은 코드들을 합칠 수 있다. malloc을 쓰는 대신 realloc을 사용하면 된다. 이는 메모리를 새로 할당하면 된다는 뜻이다.
#include <stdio.h>
#include <stdlib.h> //malloc(), free(), realloc()
int main(void){
int *list = malloc(3 * sizeof(int));
if(list == NULL){
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
// tmp 포인터에 메모리를 할당하고 list의 값 복사
int *tmp = realloc(list, 4 * sizeof(int));
if ( tmp == NULL){
return 1;
}
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 list의 네 번째 값 저장
list[3] = 4;
// list의 값 확인
for (int i = 0; i < 4; i++){
printf("%i\n", list[i]);
}
// list의 메모리 초기화
free(list);
}stdlib.h 라이브러리에 있는 realloc은 이미 할당받은 기존 메모리 덩어리를 새롭게 가져오고, 원래보다 크든 작든 새롭게 설정된 크기로 바꾸는 작업을 한다. realloc이 기존 배열에서 새로운 배열로 데이터를 복사해주고 우리는 뭔가 잘못되지 않았는지 널인지 체크하고 새로운 값을 저장해주면 된다.
위의 6줄 만으로, 기존의 더 길던 코드를 대신할 수 있게 된 것이다. 아주 편리한 함수이다.
Q. 다음과 같은 방법으로 새로운 메모리로 업데이트하면 되지 않을까요?
list = malloc(4 * sizeof(int));저렇게 하게 되면 이전 메모리 덩어리들이 사라지게 된다. list를 새로운 메모리 덩어리를 저장하도록 바꾸게 되면 기존의 메모리 덩어리는 컴퓨터 어딘가에 떠다니고 있을 것이다. 하지만 여기를 가리키는 포인터는 아무것도 없게 된다. 여기를 가리키는 화살표의 개념이 더 이상 남아있지 않은 것이다. 이것이 바로 우리가 임시 변수를 하나 만들어서 우리가 할당한 메모리를 놓치지 않도록 해야 하는 이유이다.
Q. tmp를 정수 포인터로 초기화하고 배열로 사용하게 되면 문제가 발생할까요?
발생하지 않는다. 배열은 메모리의 덩어리이기 때문이다. 그리고 C에서는 대괄호 기호를 간단한 연산을 통해 메모리의 어떤 부분으로 이동하는데 사용할 수 있기 때문이다. [0], [1], [2]처럼 말이다.
지난 주에는 malloc과 free를 배웠고 이번주에는 realloc을 배웠다. 이제 원하는 만큼 메모리를 할당하는 기초적인 수준의 방법을 알았다. 더 강력하고 일반적인 목적의 방법이다. 결국 이 함수들은 모두 메모리의 덩어리들, 즉 연속적인 메모리인 바이트들을 반환해주는 것이다. 그렇기 때문에 여러분은 확실히 대괄호 기호를 사용할 수 있다. 배열은 본질적으로 메모리의 덩어리이기 때문이다. malloc은 메모리 덩어리를 반환해주고, 그러므로 이를 배열로 생각할 수 있다. 이 관점에서 둘은 같은 것이다.
배열만큼 사용자에게 친숙한 기능을 많이 제공하지는 않는다. 예를 들어서 배열은 자동으로 free를 해준다. 따라서 우리는 지난시간까지는 배열을 free하지 않았다. 배열은 컴파일러를 통해 자동으로 이 과정을 진행해준다.
생각해보기
이미 할당된 메모리의 크기를 조절할 때 임시 메모리를 새로 할당해줘야 하는 이유는 무엇인가요?
메모리를 할당하게 되면 지정할 때 '입력한 크기만큼의 메모리만' 만들어지게 된다. 배열을 사용할 때 메모리는 연속적인 공간으로 이루어져야 하는데, 할당받은 메모리 주변으로는 다른 값들로 가득 차있을 수 있으므로 이미 할당된 메모리의 크기를 변경할 수 없다.
따라서 이미 할당된 메모리의 크기를 조절하기 위해서는 alloc함수나 realloc함수를 이용하여 임시 메모리를 새로 할당해주어야 한다. 그렇게 되면 원하는 크기의 메모리를 연속적인 공간에 새로 할당할 수 있게 되므로 배열의 기능을 하게 된다.
3. 연결 리스트: 도입
들어가기 전에
우리는 여러 자료형의 데이터를 메모리 상에 저장하고 읽고 삭제하는 방법을 배웠습니다. 컴퓨터 프로그램은 이러한 데이터를 이용해서 다양한 작업을 수행할 수 있습니다. 하지만 좀 더 복잡한 프로그램을 구현하다 보면 기본적인 포인터 구조만 이용해서 메모리를 관리하기에는 다소 번거로울 때가 많습니다. 만약 메모리를 좀 더 효율적으로 관리하고 사용할 수 있다면 어떨까요? 이번 강의에서는 데이터 구조의 개념과 연결 리스트에 대해 알아보겠습니다.
학습 목표
연결 리스트의 정의를 설명할 수 있습니다.
핵심 단어
- 연결 리스트
학습하기
일반적으로 자료 구조란, C나 C++, 자바, 파이썬에 있는 프로그래밍 구조이다. 자료 구조는 우리의 컴퓨터 메모리에 정보를 각기 다른 방법으로 저장할 수 있도록 해준다.
오늘 C에서 우리가 할 것은 이 세 가지 기능으로 만들 수 있다.

1. 구조체(struct)
C에서 자신만의 구조를 만들 수 있는 키워드였다. 2주 전에 우리는 이름과 번호가 들어가 있는 person 구조체를 만들었다. 이처럼 두 개의 값을 가진 우리만의 자료 종류를 만들 수 있다.
2. 점 표기법(.)
구조체의 속성값을 가져올 때 유용하다. 그렇기 때문에 person 구조체의 이름이나 번호를 가져오려면 변수 이름과 점 연산자를 사용해서 자료 구조 안으로 들어가야 한다.
3. 별표 연산자(*)
서로 다른 맥락에서 다른 의미를 가지지만, 지난주와 마찬가지로 항상 메모리와 관련되어 있다. 이 연산자는 메모리 덩어리로 접근할 수 있는 역참조 연산자이다. 포인터를 이용해서 말이다.
연결 리스트
값들의 리스트를 저장하는 방법이다.
배열도 이러한 값들의 리스트로 저장할 수 있었다. 하지만 배열에는 단점이 있었다. 배열은 고정된 메모리 덩어리이다. 따라서 배열의 크기를 조절해서 더 많은 값을 넣고 싶다면 최소한 더 많은 메모리를 할당하고 기존 배열에서 새 배열로 이 모든 값을 복사해야만 했었다. realloc은 이를 더 간단하게 만드는 기능이지만, 결국에는 같은 작업을 하는 것이다. 값을 복사하고 메모리를 free하고 등등 이 모든 일이 실행되어야 한다. 그래서 배열에 값을 추가하는 과정은 O(n)이다. 배열 전체를 새 공간에 복사하는데 시간이 오래 걸리기 때문이다.
그렇다면 배열의 장점은 무엇일까? 대괄호를 이용해서 문법적으로 쉽게 인덱싱할 수 있고, 랜덤 접근이라는 방법으로 일정한 시간에 접근할 수 있다. 무엇이 어디 있는지 알 수 있다는 면에서 랜덤은 아니다. 괄호에 0, 1, 2 등을 써서 바로 그 자리에 접근할 수 있다. 그래서 배열은 아주 빠르다. 또한 배열은 바이너리 검색 같은 곳에 적용할 수 있다.
하지만 메모리를 좀 더 똑똑하게 써보자. 모든 요소들을 서로서로 옆에 붙이면서 계속 추가할 수 있을 만큼 메모리가 남아있길 바라지 않고 말이다.
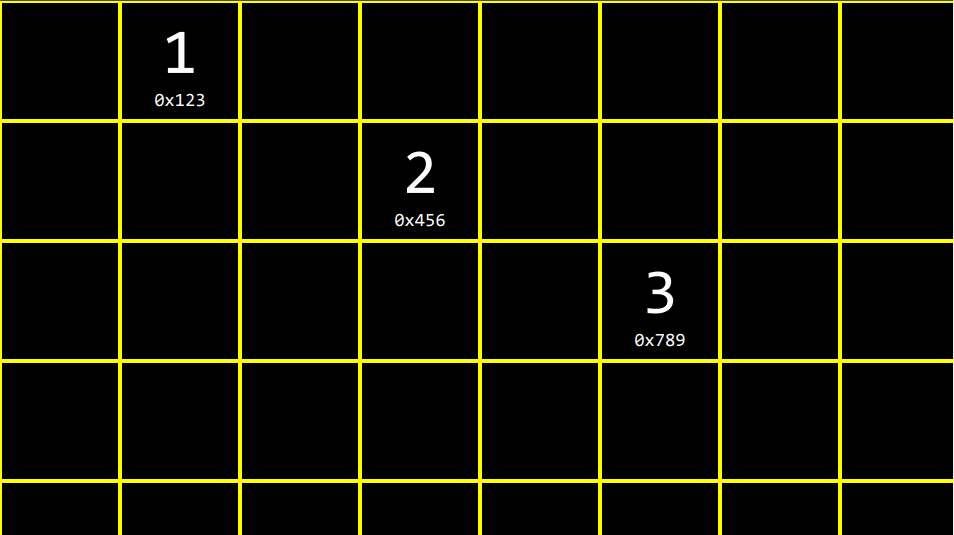
만약 1을 임의로 0x123에 저장한다 하자. 지난 시간에 컴퓨터에 있는 모든 바이트는 어딘가에 저장된다고 했기 때문이다. 이것이 크기가 1인 배열이라고 생각하고, 이 배열에 두 번째 값을 넣고 싶다고 생각해보자. 아니면 좀 더 일반적으로 리스트라고 부르자. 실제 현실의 리스트처럼 값으로 이루어진 리스트이다.
이 리스트의 크기는 1이다. 이 메모리에는 아주 많은 EMMA들이 방해하고 있을 것이다. 검은색 칸들은 모두 사용할 수 없다. 하지만 컴퓨터 메모리의 저 아래에 약간의 공간이 비어있다고 하자. 그래서 사용할 수 있는 가장 가까운 공간인 0x456에 2를 넣고, 0x789에 3을 넣었다.
이것은 정의상 배열이 아니다. 1, 2, 3이 서로 인접해있지 않기 때문이다. 여기서는 대괄호를 사용할 수 없다. 왜냐하면 2주차에서 배운 대로 값들이 서로 붙어있어야(연속적) 하기 때문이다. 위 그림에서는 1, 2, 3이 모두 멀리 떨어져 있다. 왜냐하면 컴퓨터 메모리에서 이 공간들만 사용할 수 있었기 때문이다.

약간의 사치를 부려서 1, 2, 3과 같은 값을 저장하기 위한 하나의 메모리 덩어리만 사용하지 않고 두 배의 메모리를 주어서 조금 더 유연하게 만들어보자. 그래서 이제 이 두 개의 덩어리의 묶음을 각각 1, 2, 3을 나타내게 된다. 그럼 나머지 반은 어디에 사용하면 좋을까? 다음 메모리 덩어리의 주소이다.
예를 들어 이 리스트를 정렬된 상태로 유지하는 것이 목표라서 1, 2, 3을 담은 리스트를 만들고 싶다면, 이걸 지도나 빵 부스러기 같은 용도로 사용하면 어떨까? 즉 다음 메모리의 덩어리를 가리키도록 하는 것이다.
그리고 마지막인 3의 메모리에는 이 리스트에 더 이상 남은 것이 없다는 것을 나타내기 위한 특별한 값인 'NULL'을 가진다. 이는 문자 \0과는 엄밀히 다른 것이다. 이는 16진법 0이다. NULL은 포인터이다.
지난 주에 어떤 값이 실제로 메모리의 어디에 있는지는 중요하지 않다고 했다. 다시보자. 이 그림에서 포인터로 화살표로 나타내보자.

이제 이 1, 2, 3 숫자 리스트는 연결되어 있다. 연결 리스트는 메모리 덩어리 여러 개를 포함한 데이터 구조이다. 이들은 메모리들이 포인터로 연결되어 있고, 그 대가로 원래 배열에서는 그냥 숫자 1, 2, 3만 저장하다가 이제는 연결 리스트에서는 1, 2, 3 숫자 뿐만 아니라 3개의 포인터(다음 메모리의 주소를 가리킴)를 더 저장해서 2배의 메모리가 필요하다. 두 개의 포인터가 사용되고 있고, 나머지 하나는 리스트에 뭔가 추가된다면 그 곳을 가리키게 된다.
이제 우리는 컴퓨터 메모리에 이렇게 생긴 구조를 만들 수 있다. 우선 이 구조를 개별적으로 살펴보자. 모두 두 개의 필드를 가지고 있고, 하나는 정수이며 또 다른 필드로 리스트의 다음 요소를 가리키는 메모리 덩어리이다.

컴퓨터 공학에서 node란 직사각형으로 나타낼 수 있는 메모리 덩어리를 의미한다. 그리고 이제 node에 두 가지 값을 저장해보자.

하나의 필드는 정수인 number이다. 그리고 두 번째 필드에는 next라는 이름의 다음 node를 가리키는 포인터이다. 따라서 아래와 같이 작성할 수 있다.

하지만 이렇게 할 수는 없다. 왜냐하면 C는 문자 그대로 받아들이는데, 이 코드를 위에서 아래로, 왼쪽에서 오른쪽으로 읽으면 node라는 단어가 마지막 줄이 끝나기 전까지는 존재하지 않기 때문이다. 그래서 node 안에서 node를 쓸 순 없다. 아직 정의되지 않았기 때문에 존재하지 않는다.

이를 해결해주기 위해서, "typedef struct node"라 작성하여 사용하고자 하는 단어를 추가해준다. 그리고 나면 여기에 node *를 사용할 수 있게 된다.
이 자료 구조의 모든 node, 모든 노란색 직사각형 상자에는 숫자와 포인터가 있다. 그리고 이 포인터는 node 구조체를 가리키도록 정의되어 있다. 여기에
typedef struct 이름{
int number;
struct 이름 *next;
}별명;코드를 좀 더 길게 표현해서 아래에 존재하지 않던 node라는 표현을 써주기만 하면 된다.
Q. node를 두 번 써야하나요?
두 번 쓸 필요는 없다. 이 앞에 원하는 아무 단어나 써도 된다. typedef struct x, y, z로 적어도 된다. 하지만 그렇게 되면 struct x, struct y, struct z와 같이 써야만 한다.
typedef struct node. 이것이 이 구조체의 정식 명칭이다. 이것은 node 구조체이다. 마지막에 괄호의 끝에는 구조체의 별명을 작성해준다. 여기서는 간결하게 node다.
이것이 바로 typedef가 하는 일이다. node 구조체에서 node로의 별칭을 제공하는 것이다. 프로그램의 다른 부분에서 사용하기 쉽도록 말이다.
생각해보기
연결 리스트를 배열과 비교했을 때 장단점은 무엇이 있을까요?
배열은 메모리의 연속적인 공간에서만 사용할 수 있기 때문에 처음에 지정한 크기로 고정이 된다. 하지만 이에 비해 연결 리스트는 초기에 크기를 지정하지 않고도 원하는 데이터를 추가하여 크기를 계속 동적으로 변경할 수 있다.
그러나 숫자와 같은 데이터만 저장하는 배열과는 달리 연결 리스트는 숫자 데이터 뿐만 아니라 다음 연결 리스트의 주소지도 저장해야 하기 때문에 배열에 비해 공간이 2배 필요하므로 메모리의 공간을 더 많이 사용하게 된다.
4. 연결 리스트: 코딩
들어가기 전에
지난 강의에서 연결 리스트의 정의와 리스트의 기본 단위가 되는 구조체를 정의하는 방법을 배웠습니다. 이번 강의에서는 이 구조체를 이용하여 실제로 연결 리스트를 구현하고 사용해보도록 하겠습니다.
학습 목표
연결 리스트를 구현하고 사용할 수 있습니다.
핵심 단어
- 연결 리스트
학습하기
연결 리스트의 구현을 살펴보자.

처음에 연결 리스트는 비어있다. 그래서 아직 비어있는 연결 리스트를 구현하기 위해서 NULL로 지정한다. 들어 있는 숫자가 없다면 적어도 리스트가 없다는 것을 알려주는 변수이다. 값이 없을 때 이를 표현하는 가장 간단한 방법은 0을 저장해서 널이라는 새로운 별명을 가지도록 하는 것이다.
즉, node *를 만들고 이를 list라고 부른다음 NULL로 지정한다. 널로 초기화해주었기 때문에 아직은 어떤 메모리 덩어리를 가리키는 화살표가 없다.
node *list = NULL;이제 리스트에 숫자 2를 추가해보자. 2를 넣기 위한 공간을 할당하지 않고, "숫자 2"와 "포인터"를 넣을 공간을 할당한다. 이 둘을 합쳐서 "node"라고 부른다고 했다.
node *n = malloc(sizeof(node));
(*n).number = 2;이제 이 코드는 node를 저장할 만큼의 메모리 덩어리를 할당해준다. 그리고 malloc으로부터 반환 받은 주소를 임시로 변수 n에 저장한다.
두 번째 줄은 뭘까? node의 number을 2로 설정해준다. *n은 가리키는 곳으로 간다는 뜻이고, 괄호는 연산의 순서를 위해 넣어주었다. 그리고 점 표기법을 이용해 number라는 필드에 접근하여 2로 만들어준다.
하지만 이 코드는 너무 못생겼다. 다행히도 C에는 이를 더 간단하고 예쁘게 표현할 수 있는 문법이 있다. 바로 화살표 기호이다. 이는 위의 코드와 같은 코드이다.
2에 해당하는 새로운 node를 할당한 다음에 할 일은 다음 주소에 NULL를 추가한다.
node *n = malloc(sizeof(node));
n -> number = 2;
n -> next = NULL;하지만 malloc을 사용할 때마다 검사를 하여 반환된 값을 항상 체크해야 한다. 그래서 아주 정밀하게 코드를 짜기 위해서 n이 널이 아닌지 검사를 꼭 해준 후에 나머지 부분을 실행해주어야 한다. 반대로 n이 널이면 프로그램을 끝내거나 return해도 된다.
중요한 것은, n이 널인지 아닌지 확인되기 전까지는 n을 건드리거나 화살표 기호를 사용해서는 안된다!
node *n = malloc(sizeof(node));
if (n != NULL){
n -> number = 2;
n -> next = NULL;
}여기까지 한 과정을 아래 그림과 같이 나타낼 수 있다.

하지만 이것은 아직 연결이 이루어지지 않았기 때문에 연결 리스트가 아니다. 우리는 어떤 포인터에서 어떤 구조체로 향하도록 하는 것과 같은 행동을 꼭 해야만 한다.

화살표를 구현하기 위해서, 다음과 같이 코드를 작성할 수 있다.
list = n;list라는 변수가 있고 원래는 널로 초기화되어 있었지만, 새로운 node의 주소를 가지고 있는 임시 변수인 n을 저장해주는 것이다. 그래서 이제 list는 더이상 널이 아니라고 할 수 있다. 방금 할당한 메모리 덩어리의 주소와 같은 값인 n을 넣음으로써 말이다.
만약 여기서 또 리스트에 숫자 4를 추가하고 싶다고 해보자.

4는 자체 node안에 들어있기 때문에 4를 넣기 위한 새로운 node를 할당받는다.
node *n = malloc(sizeof(node));
if (n != NULL){
n -> number = 4;
n -> next = NULL;
}하지만 여기서 다가 아니다. 여기서 끝내면 4가 든 저 node는 어디에도 소속되지 않는 node가 된다. 화살표 하나를 추가해야 한다.

여기서 list가 아닌 2의 포인터가 4를 가리키도록 해야 한다.
지난주에 사용한 변수 tmp를 이용해서 포인터를 나타내보자. 처음에는 가서 list가 가리키고 있는 것과 같은 것(2)을 가리키게 된다. 그리고 이 구조체(2)의 next가 널인지 체크한다. 만일 널이라면 리스트의 끝을 찾은 것이다. 그럼 이제 이 화살표를 따라가면 여기가 널 포인터라는 것을 알게 되었고 2의 next에서 4로 화살표를 그려주면 된다.
node * tmp = list;
while (tmp->next != NULL){
tmp = tmp -> next;
}
tmp -> next = n;이를 코드로 나타내면 다음과 같다. list에서부터 시작해서, 널이 아니라면 계속해서 자신을 다음 가리키는 값으로 업데이트한다. 그리고 마지막에 오면 마지막의 다음을 n(4)를 가리키는 주소로 저장해준다.
여기서 마지막으로 새로운 숫자인 5를 추가해준다고 하자.

5를 리스트에 정렬해서 넣을려면 4의 다음에 넣어야 할 것이다.

그리고 다시 생각해야할 것은, 이것들은 컴퓨터 메모리에 흩어져 있다. 일렬로 배치되어 있지 않다. 사용 가능한 공간이 어디 있는지는 크게 상관없기 때문이다.
만약 첫 부분에 1을 넣고 싶다면?

이 리스트의 순서를 유지하기 위해서는 이 숫자 1이 있는 부분에서 어떤 점을 고려해야 할까?
처음 정렬을 하고 싶다면 리스트의 시작부분에 1을 넣을 것이다. 그래야 화살표가 왼쪽에서 오른쪽에서 간다.
node *n = malloc(sizeof(node));
if (n != NULL){
n -> number = 1;
n -> next = NULL;
}그래서 새로운 node를 할당하는 코드를 사용하고, 화살표를 아래와 같이 바꾼다.

하지만 여기서 1의 next가 NULL이므로 2, 4, 5가 버려졌다. 더 이상 2를 아무것도 가리키지 않으면 2와 4, 5가 버려진다. 이것이 바로 메모리 누수이다. valgrind를 사용할 때 메모리가 누수되어서 valgrind가 경고를 발생시킨다면 아마 메모리를 free하는 것을 잊었기 때문일 것이다. 아니면 더 심한 경우는, 위와 같이 우리가 사용하던 메모리를 완전히 잃어버린 것일 수도 있다. 메모리에 다시는 접근할 수 없는 것이다. 컴퓨터에 요청할 순 있지만 다시 되돌려받을 순 없다. 이 값들이 어디에 있는지 기억하고 있는 변수가 없기 때문이다. 따라서 위와 같이 작성하면 안된다.

먼저 1이 2를 먼저 가리켜서 list와 중복시키도록 한다. 이제 리스트의 시작점이 어디인지 충돌이 생긴다. 하지만 1은 2를 가리키고 있으니 다음은 리스트를 바꾸면 된다. 리스트를 1로 바꾸면 된다.

1을 가리키고 있는 방금 할당한 새로운 node의 next 필드를 업데이트할 때 lsit가 가리키고 있는 곳을 가리키도록 만든다. 다시 말하자면 이것을 리스트가 가리키는 것과 같은 곳을 가리키도록 하려면 n->next 를 list가 가리키는 곳으로 지정하면 된다. 그리고 list는 n 그 자체를 가리키도록 하면 된다.
n -> next = list;
list = n;
만일 연결 리스트 중간에 3을 추가하고 싶은 경우에는 어떻게 하면 될까?

node에 사용하기 위한 메모리를 받고, 바로 2가 3을 가리키도록 하면 4와 5가 버려지게 되므로 그렇게 하면 안된다. 3을 먼저 4를 가리키도록 만든 후에 2가 3을 가리키도록 업데이트를 한다.

하지만 이 과정을 하기 위해선 "루프"를 이용해 원래 존재하던 리스트를 탐색하고 부등호를 사용해서 삽입할 적절한 위치를 찾아내야 한다. 따라서 이 일을 하기 위해 포인터를 만들어야 한다.
일반적으로는 맨 뒤에 새로운 값을 추가하는 것이 제일 쉽고, 그 다음에는 맨 앞에 추가하는 것이 쉽다. 순서를 지키는 것이 중요하지 않은 경우에 말이다.
완성된 코드는 아래와 같다.
#include <stdio.h>
#include <stdlib.h>
//연결 리스트의 기본 단위가 되는 node 구조체를 정의합니다.
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 name으로 지정합니다.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정합니다.
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터를 정의합니다. 연결 리스트의 가장 첫 번째 node를 가리킬 것입니다.
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL 로 초기화합니다.
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킵니다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장합니다. “n->number”는 “(*n).numer”와 동일한 의미입니다.
// 즉, n이 가리키는 node의 number 필드를 의미하는 것입니다.
// 간단하게 화살표 표시 ‘->’로 쓸 수 있습니다. n의 number의 값을 1로 저장합니다.
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화합니다.
n->next = NULL;
// 이제 첫번째 node를 정의했기 떄문에 list 포인터를 n 포인터로 바꿔 줍니다.
list = n;
// 이제 list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장합니다.
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node입니다.
//이 node의 다음 node를 n 포인터로 지정합니다.
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number과 next의 값을 저장합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫번째 node를 가리키고, 이는 두번째 node와 연결되어 있습니다.
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의
// 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정합니다.
list->next->next = n;
// 이제 list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력합니다.
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 이 것이 for 루프의 종료 조건이 됩니다.
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제해주기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줍니다.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}
생각해보기
연결 리스트의 중간에 node를 추가하거나 삭제하는 코드는 어떻게 작성할 수 있을까요?
<node 추가>
Node *new_node = (*Node)malloc(sizeof(Node));
Node *tmp = root;
int k = 추가할 위치;
for (int i = 0; i < k; i++){ //추가할 위치까지 이동
tmp = tmp->next;
}
new_node->next = tmp->next;
tmp->next = new_node;<node 삭제>
Node* tmp = root;
int k = 삭제할 노드의 위치;
for (int i = 0; i < k-1; i++){ //삭제할 노드 전까지 이동
tmp = tmp->next;
}
Node* delete = tmp->next;
tmp->next = tmp->next->next;
free(delete);
5. 연결 리스트: 시연
들어가기 전에
이번 강의에서는 학생들과 함께 연결 리스트를 직접 시연해보도록 하겠습니다. 또 연결 리스트와 배열을 비교해보고 그 장단점을 생각해 보겠습니다.
학습 목표
연결 리스트와 배열의 장단점을 설명할 수 있습니다.
핵심 단어
- 연결 리스트
- 배열
학습하기

2->4->5->1->3 으로 추가하는 과정을 시연을 통해 보았다.
연결 리스트는 배열과 같이 메모리 덩어리들로 이루어져있다. 하지만 컴퓨터는 한 번에 하나의 메모리만 볼 수 있다. 이 말은 컴퓨터에게는 아래와 연결 리스트가 아래와 같이 보인다는 것이다.

연결 리스트에 있는 숫자들은 아무것도 보이지 않고 모든 메모리를 하나씩 열어봐야 한다. 그렇기 때문에 3이 어디로 가고, 5나 1이 어디로 가는지 알려면 각각의 값을 찾기 위해서 최대한으로는 모든 문을 열어야만 한다.
연결 리스트를 이용해서 우리는 하나의 기능을 얻었다. 바로 리스트에 동적으로 추가할 수 있는 기능을 확보했다는 것이다. 즉 계속해서 추가적인 숫자들을 malloc할 수 있어서 원하는 만큼 리스트를 크게 만들 수 있다. 위의 경우는 5번이었지만, 50번, 500번 더 숫자를 추가할 수 있다.
즉, 연결 리스트의 장점은 배열처럼 숫자를 추가하기 위해서 크기를 조절하고 기존의 값을 모두 옮기지 않아도 된다는 것이다. 그냥 메모리의 누군가가 누군가를 가리키기만 하면 된다.
그러므로 우리 자료구조를 이런 연결 리스트로 만들면 역동성을 추구한 것이다. 원래 있었던 것을 움직이지도 않고 리스트를 늘릴 수 있는 능력이다.
하지만 이런 능력을 대가로 어떤 단점이 있을까? 임의의 접근을 할 수 없다.
리스트의 처음부터 끝까지 가기 위해서는 포인터를 따라 가야하고 중간의 값으로는 바로 갈 수 없다. 위의 사진을 보면 3이 확실이 가장 중간에 있다는 것을 바로 볼 수 있지만, 컴퓨터라면 이것을 알 수 없다. 이 자료 구조를 저장하는 주요 변수가 포인터라면 모든 화살표를 가리키면서 하나하나 세어보면서 그제서야 저기에 5가 있으니 중간 값을 저 앞에서 이미 지나쳤다는 것을 알게 된다. 따라서 임의 접근을 할 수 없게 된다.
임의 접근을 하게 되면 이진 탐색 알고리즘을 잘 할 수 있게 된다. 그래서 예전처럼 이진 탐색을 효과적으로 할 수 있는 능력을 잃게 된다.

이제 연결 리스트의 실행 시간을 살펴보면 안타깝게도 나빠졌다는 것을 알 수 있다.
탐색은 log n 이었던 이전과 달리 다시 O(n)이 되었다. 리스트의 끝이나 중간을 찾기 위해서는 모든 화살표를 따라 가야봐야하고 어떤 장소로 바로 갈 수 없기 때문이다.
한편 삽입의 경우에는 최악의 경우도 O(n)이 된다. 왜냐하면 모든 리스트를 다 둘러보고 주어진 숫자에 맞는 자리를 찾기만 하면 되기 때문이다. 순서를 맞추고 싶은 경우 말이다.
따라서 훨씬 더 동적인 삽입 기능을 얻어서 realloc에서 했던 것처럼 값들을 이동하지 않아도 되기 때문에 실행 시간이 줄어들 것이라고 생각할 수 있지만 사실 대가가 있다.
// Implements a list of numbers with linked list
//1->2->3 add number
#include <stdio.h>
#include <stdlib.h>
// node 표현
typedef struct node {
int number;
struct node* next;
}node;
int main(void){
//크기 0인 리스트 (초기화)
node *list = NULL;
// Add number to list
node *n = malloc(sizeof(node));
if (n == NULL){
return 1;
}
n->number = 1;
n->next = NULL;
list = n;
// Add number to list
n = malloc(sizeof(node)); //같은 변수 n이지만 malloc을 사용해서 아까와 다른 주소가 들어옴
if (n == NULL){
return 1;
}
n->number = 2;
n->next = NULL;
list->next = n;
// Add number to list
n = malloc(sizeof(node));
if(n == NULL){
return 1;
}
n->number = 3;
n->next = NULL;
list->next->next = n;
// Print list
for (node *tmp = list; tmp != NULL; tmp = tmp->next){
printf("%i\n", tmp->number);
}
// Free list
while (list != NULL){
node *tmp = list->next;
free(list);
list = tmp;
}
}
생각해보기
배열이 정렬되어 있지 않은 경우의 검색 소요 시간을 연결 리스트의 검색 시간과 비교해보세요.
배열이 정렬되어 있지 않은 경우, 최악의 경우에 연결 리스트는 처음부터 끝까지 검색을 모두 해봐야 하므로(n번) O(n)이다.
6. 연결 리스트: 트리
들어가기 전에
연결 리스트를 활용해서 보다 더 다양한 데이터 구조를 만들 수 있습니다. 연결 리스트에서는 각 요소가 다른 요소를 하나씩만 가리키고 있었습니다. 만약 가리키는 요소가 여러개가 된다면 어떤 장점과 단점이 있을까요? 이번 강의에서는 ‘트리’라는 연결 리스트 기반의 자료 구조를 알아보겠습니다.
학습 목표
트리의 구조를 설명하고 활용하는 코드를 작성할 수 있습니다.
핵심 단어
- 트리
- 루트
Q. 배열에 비해서 더 퇴보적인 것 같다. 배열에서는 모든 것을 기존 배열에서 새로운 배열로 복사해야 해서 조금 오래 걸리긴 하지만, 크기를 바꿀 수 있고 임의 접근을 통해서 이진 탐색도 쓸 수 있어서 정렬된 리스트에서 탐색할 때 실행 시간이 log n이기 때문이다. 우리는 이 기능을 포기한 게 아닐까요?
연결 리스트는 역동성을 준다. 값들을 옮기느라 시간을 낭비하지 않고 일을 할 수 있다. 하지만 임의 접근을 할 수 없다.
하지만 포인터와 자료 구조를 사용해서 메모리에 여러 요소를 잇고 화살표를 이용하여 붙여서 더 멋진 무언가를 만들 수 있다. 만일 1차원적인 자료 구조만 계속 만드는 것이 아니라면? 배열과 연결 리스트는 왼쪽과 오른쪽으로만 움직인다.
수직적인 개념을 사용해서 더 흥미로운 방식으로 요소를 배열한다면 어떤 이점이 있을까? 배열과 연결 리스트의 장점만 가져온다면? 여기 아래에 그 방법이 있다.
트리

이전에 책의 오른쪽과 왼쪽을 찾는 예시를 생각해보자. 이 일이 실제로 2차원적으로 일어난다고 생각하면 아래와 같다.

1~7이 들어 있는 같은 배열이지만 서로 다른 높이에 표시되어 있다.
중간에서 시작한다. 그리고 왼쪽이나 오른쪽으로 간다. 즉, 같은데 2차원적으로 표현되는 것이다. 이진 정렬을 가지고 했던 과정을 말이다. 이는 연결 리스트와 비슷하다. 그리고 이것은 연결 리스트이기 때문에 모든 것을 1부터 7까지 차례대로 붙일 필요가 없다.
여기에 더 많은 공간을 할당하고 자료 구조들을 이어 붙여서 더 많은 포인터들을 추가하여 개념상 2차원으로 만들어보자.
node가 꼭 하나의 포인터만 가져야 할 필요는 없다. 새로운 구조체를 만들어서 두 개의 포인터를 가진 node를 만들고, 각 포인터를 left, right로 지어준다. 이전에는 next라는 포인터 하나만 있었지만, 두 개의 포인터를 가진 더 멋진 구조체를 만들 수 있으니 말이다.
typedef struct node{
int number;
struct node *left;
struct node *right;
}node;이는 가계도 같은 '트리'를 만드는 데 사용된다. 더 정확하게는 '이진 탐색 트리'라고 부른다.

트리의 노드들이 모두 최대 두 개의 자식 노드가 있어서 이진법의 '이진'을 따와서 최대 2라는 것을 표현한다. 아래는 0개의 자식을 가지고, 최대 2개의 자식 노드를 가진다.
순서를 맞추기 위해 신경을 썼다는 의미에서 '탐색'트리이다. 트리에 있는 모든 노드는 왼쪽 자식은 더 작고, 오른쪽 자식은 더 크다. 이것이 재귀적 정의이다.
그렇다면 이의 장점이 뭘까? 이진 탐색을 다시 할 수 있게 된다. 포인터를 이용했기 때문에 연결 리스트처럼 역동성도 가진다. 숫자 0이나 8을 넣고 싶다면 0은 젤 왼쪽, 8은 젤 오른쪽으로 간다. 배열에서 한 것처럼 할 필요없이 숫자들을 추가할 수 있다.
루트
하지만 추가적으로 화살표로 요소들을 잇고 있기 때문에 메모리의 어디에 있든 간에 트리라고 불리는 이 자료 구조를 계속하여 저장해야 한다. 하나의 포인터가 이 '루트'라고 불리는 것을 가리켜야 한다.
만약 7을 찾는다고 한다면, 먼저 4로 간다. 7은 4보다 크므로 오른쪽으로 간다. 그러면 트리의 왼쪽 반은 무시하게 된다. 6으로 가서 다시 한번 7과 비교하고 오른쪽으로 간다.
트리의 높이는 밑이 2인 로그를 따른다. 이 트리에서 7개 요소가 있다면 어떤 값을 찾는 데에는 3단계 밖에 걸리지 않는다. 필요한 단계 수가 O(n)이 아닌 것이다.
또 이는 재귀에 가장 적합한 방법이다. 재귀적으로 정의되어 있다는 말은 "어떤 노드에서라도 왼쪽이 더 작고 오른쪽이 더 크다는 것"이다.
이런 이진 탐색을 구현하면 무엇을 할 수 있는지 예시를 통해 알아보자.
아래는 숫자 50이 트리에 있으면 true, 아니면 false 반환하는 search함수이다.
bool search(node *tree){
if (if tree == NULL){
return false;
}else if (50 < tree->number){
return search(tree->left);
}else if (50 > tree->number){
return search(tree->right);
}else{
return true;
}
}우선 "트리의 루트의 주소"를 입력 받는다. 그리고 전달 받은 주소가 NULL인 빈 주소를 받았다면 false를 반환한다. 트리가 없기 때문이다. 다음으로 50이 tree->number보다 작다면 왼쪽 서브 트리로 가서 탐색을 한다. 따라서 재귀를 적용할 수 있다. 그리고 50보다 크다면 오른쪽으로 간다.
그리고 마지막으로 tree가 존재하는데, 50보다 크지도 작지도 않다면(else) 우리가 찾는 값인 50과 같다는 말이므로 true를 반환한다.
이진 탐색 트리의 탐색 속도
그렇다면 이진 탐색 트리의 탐색 속도는 어떨까? 실행 시간 상한은 우리의 목표였던 다시 log n이 된다.
그럼 작은 수만 혹은 큰 수만을 계속적으로 추가하게 되면 트리가 균형직이지 않고 얇고 길게 되지 않을까? 그래서 이진 검색 트리의 균형을 유지할 수 있는 알고리즘이 있다. 어떤 값을 넣으면 요소들이 움직이는 것이다. 메모리에서 제거하지 않고 포인터만 변경하여 자료 구조가 아주 높아지지 않도록 한다. 이렇게 해도 실행 시간은 log n 이다. 이진 탐색이 가능한 배열과 같은 실행 시간을 가진다.

역동성을 가지는 연결 리스트는 크기를 줄이거나 늘릴 수 있었으나 이진 탐색이 불가했다. 그렇지만 공간을 더 사용해서 노드에 포인터가 두 개씩 들어가게 하면 탐색하는 시간을 log로 단축시키는 상황이 된다.
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}
생각해보기
값을 검색할 때 이진 검색 트리가 기본 연결 리스트에 비해 가지는 장점과 단점은 무엇이 있을까요?
연결 리스트는 각 노드마다 차지하는 공간이 2였지만, 이진 검색 트리는 포인터가 하나 더 추가되면서 3으로 늘어나게 된다. 따라서 메모리를 사용하는 공간이 더 많아지게 된다.
하지만 연결 리스트는 실행 시간의 상한이 O(n)이었으나 이진 검색 트리를 사용하게 되면 이 시간이 O(log n)으로 엄청나게 줄어들게 되면서 탐색 시간을 대폭 단축시킨다는 장점이 있다.
7. 해시 테이블
들어가기 전에
연결리스트나 트리에서는 값을 검색할 때 O(n) 또는 O(log n)의 시간이 걸렸습니다. 이 시간을 조금 더 단축해서 거의 O(1)에 가깝게 할 수는 없을까요? 이번 강의에서는 이를 가능케 해주는 ‘해시 테이블’ 이라는 자료 구조에 대해 알아보겠습니다.
학습 목표
해시 테이블의 원리와 구조를 설명할 수 있습니다.
핵심 단어
- 해시 테이블
- 해시 함수
해시 테이블

실행 시간에 대한 위의 리스트에서 올라갈 수록 느리고 내려갈 수록 빠르다. 그렇다면 O(1)과 같이 일정한 시간을 가지는 자료 구조를 발견한다면 좋지 않을까? 만약 어떤 것을 자료 구조에 넣고 찾을 때 한 번에 할 수 있다면 정말 좋을 것이다. 그렇게 되면 O(n)인지 O(log n)인지 신경쓰지 않아도 원하는 값으로 바로 접근할 수 있기 때문이다.
이론적으로 이를 가능하게 해주는 것이 "해시 테이블"이다.
해시 테이블은 배열과 연결 리스트를 조합한 것이다. 편의를 위해 가로로 표현한 배열을 보자. 여기서 목표는 이름표들을 잘 정렬하는 것이라 해보자. 큰 행사가 열려서 미리 만든 이름표들을 사람들이 아주 효율적으로 가져가도록 할 것이다. 만약 A부터 Z까지 알파벳 순서로 정렬했다 해도 방 안의 사람들이 모두 줄을 서서 모든 이름표를 뒤져서 자기 이름표를 찾아야 하므로 효율적인 시스템은 아니다.
다행히도 라벨이 달린 바구니 몇 개를 준비해서 각자 이름표를 찾기 위해 모든 이름표를 뒤지는 대신 자신의 바구니로 가서 자신의 이름을 찾아낼 수 있도록 한다. 그 철자로 시작하는 이름이 자기 자신 뿐이라면 한 번에 찾을 수 있을 것이다.
이의 구현 과정을 한 번 보자. 해시 테이블에서는 단어나 이름이 같은 입력값이 들어오면 그 단어에 포함된 문자를 보고 어디에 그 이름을 넣을지 결정하는 방식이 흔하게 사용된다.

여기 다음과 같이 0~25까지 26칸의 배열이 있고, A부터 Z까지 순서가 정해져 있다고 생각해보자.
지금 목표는 학생들이 이름표를 가져갈 수 있도록 이 이름표들을 미리 저장하는 것이다. 첫 번째 이름표는 Albus이므로 0번 바구니에 넣는다. Zacharis 이름표는 25번 바구니에 넣는다. 배열에서는 임의 접근을 할 수 있으므로 한 번에 넣을 수 있다. 다음 Hermione도 H로 시작하므로 7에 넣는다. Ginny는 6에, Ron은 17에 넣는다. ...

위의 학생들은 바구니에서 아무 이름표나 가지고 바로 갈 수 있다. O(n)이 아니다. 하지만 위의 상태에서 'Harry' 이름표를 넣으면 어떻게 될까? 7번에 넣어야 하는데 이미 이름표가 있다. 하지만 배열을 사용할 뿐 아니라 연결 리스트도 사용하여 해시 테이블이라는 자료 구조를 사용하고 있다. 따라서 가로로 연결 리스트를 만들면 된다.
Hermione와 Harry의 이름표를 연결하여 두 단계만에 두 이름표 모두 찾을 수 있도록 하는 것이다. 하지만 이름표를 찾는데 걸리는 시간은 여전히 O(n)이 아니다.

해시 함수
위 구조가 바로 해시 테이블이다. 그리고 인덱싱을 하는데 사용하는 이 배열은 해시 함수라고 한다.

해시 함수는 이전 함수, 프로그램과 같이 입력값을 받아 출력값을 보내는 것이다.

이는 어떤 함수이자, 과정이자, 알고리즘이다. 이름을 넣어주면 어느 바구니로 가야하는지 알려주는 것이다. 그리고 우리는 실제로 첫 번째 글자를 살펴서 이름표를 바구니로 연결하는 해시 함수를 사용하였다. 왜냐하면 이는 가장 간단하기 때문이다.

만일 여기에 Albus를 해시 함수에 넣으면 0이 반환되어 0번째 배열, 즉 A에 해당하게 된다.

Zacharias를 넣으면 25가 나온다. 첫 글자가 Z이기 때문이다.
이건 좀 단순하다. 그리고 우리는 문제를 발견했다. 이름의 첫 번째 글자만 본다면, 만약 세상에 H나 L로 시작하는 이름이 엄청 많은 극단적인 상황을 떠올리게 되면 모든 이름표가 특정 바구니에 쌓여있게 된다. 따라서 해시 테이블이 굉장히 효율적일지 몰라도, 이런 경우를 생각하면 최악의 경우 O(n)의 시간이 추가하거나 탐색할 때 필요로하게 된다.
그럼 이 문제를 어떻게 해결할 수 있을까? 단순히 첫 글자만 보지 않고 첫 두 글자를 보는 건 어떨까?

그렇게 되면 26개보다 훨씬 더 많은 바구니들이 필요하게 된다. 26 * 26 = 총 676개의 바구니가 필요하다. 공간은 더 많이 필요하지만 충돌할 확률은 낮아진다. 이제는 이름을 찾을 때 한 번에 찾게 된다.
하지만 Hagrid가 들어가게 될 경우에 둘다 HA가 들어가서 충돌이 발생한다. 따라서 두 글자를 보는 것도 이상적인 방법은 아니다. 676개의 바구니가 있어도 여전히 충돌 문제가 발생한다.
그렇다면 여기서 더 발전시켜서 첫 세 글자를 보도록 하자. 그러면 충돌할 확률은 아주 낮아지지만 배열의 칸들이 아주 많아지게 된다. 하지만 HA대신 HAA, HAB, HAC, .. HAG부터 HAQ... HES도 있다. 아주 많은 바구니들이 있다.

여기에 Harry, Hagrid, Hermione의 이름을 해시하면 모든 다른 바구니에 들어가게 된다. 개선되었다고 할 수 있다. 실제로도 이제 탐색하면 한 번에 찾을 수 있게 된다.
하지만 어디까지나 H로 시작되는 이름이 그렇게 많지 않다고 가정했을 때이다. 따라서 여전히 해시 테이블의 실행 시간은 O(n)이다. 왜냐하면 운 나쁘게 비슷한 이름이 한 무더기 들어오게 될 수도 있기 떄문이다.
따라서 처음으로 다시 돌아가 Harry, Hermione, Hagrid를 연결하는 것이 더 낫다. 그리고 그냥 이름표를 찾는데 시간이 좀 더 걸리는 것이다.
그렇기 때문에 시간과 공간 사이에 균형이 필요하다. 하지만 어떤 이상적인 해시 함수를 가지고 있어서 이름표들이 각각 다른 결과를 가져서 서로 충돌이 일어나지 않도록 하는 엄청난 알고리즘을 코드로 구현할 수 있다면 정말 대단한 O(1),즉 일정한 실행 시간을 가질 수 있다.
실제로 이를 파이썬으로 살펴보면 대부분의 컴퓨터 시스템은 최대한의 노력을 기울여서 해시 테이블이 보통 O(n)까지 커지지 않는다. 평균적으로 더 빠르다. 하지만 이론적으로는 느려질 수 있는 위험성이 있다.

그래서 엄밀히 말하면 탐색하는 실행 시간이 O(1)이 될 수도 있다. 이는 모든 이름표가 모두 다른 바구니에 들어간다는 가정하에 말이다. 하지만 여전히 H로 시작하는 이름이 너무 많은 운 나쁜 일이 일어날 수도 있다.

따라서 엄밀히 말하자면 해시 테이블은 O(n)이다. 하지만 바구니에 Hermione, Hagrid, Harry 3명이 있으면 같은 바구니에 n개의 이름이 있는 것보다는 훨씬 낫다. 그래서 실제로도 이 점근적인 상황을 없애면 훨씬 빠르다. 모든 이름을 연결 리스트나 배열에 넣는 것보다는 훨씬 빠르다.
일반적으로는 최대한 많은 바구니를 만드는 해시함수를 사용하기 때문에 거의 O(1)에 가깝다고 볼 수 있다.
8. 트라이(검색)
들어가기 전에
문자열의 길이가 일정한 경우 이 문자열들을 저장하고 관리하는데 최적의 자료 구조는 무엇일까요? 연결 리스트, 트리, 또는 해시 테이블이 최선의 방안이 될 수 있을까요? 이번 강의에서는 ‘트라이’라는 자료구조에 대해 알아보겠습니다.
학습 목표
트라이의 원리와 구조를 설명할 수 있습니다.
핵심 단어
- 트라이
트라이
검색(retrieval)의 줄임말.
트라이는 어떤 자원을 절약하기 위해 다른 자원을 소비하는 패턴을 가진다. 이에는 많은 메모리가 들지만, 자료 구조 안에 있는 이름이나 단어를 찾는 데 일정한 실행 시간을 가진다.
트라이는 각각의 노드가 배열로 이루어진 트리이다. 맨 위에 있는 배열은 트라이의 루트이다.

이 배열은 A부터 Z까지, 혹은 0부터 25까지, 총 크기가 26이다.
만약 이 트라이에 이름을 하나 저장하고 싶은 경우, 그 이름의 모든 글자들을 봐야 한다. 그래서 Harry의 경우 H a r r y이다. 그 다음은 만약 현재 저장하고 싶은 단어인 첫 글자가 H라고 하면 이에 해당하는 인덱스로 간다.

만약 거기에 자식 노드가 없다면 그 아래에 다른 트리, 혹은 가지가 없다면 새로운 노드를 할당한다. 새로운 노드는 다시 말해 새로운 배열이다. 이제 화면에 두 배열을 그렸다. 두 번째 배열에는 A를 표시한다. 사실상 0~25까지 26개의 글자가 항상 있다. 하지만 예시에 중요한 글자들만 표시(A)했다.

여기 H, a, g가 있다. 이제 이 자료 구조에 우리가 저장하고 싶은 이름은 Hagrid인가보다. 이 배열에는 g를 표시했으니 이제 r로 간다. 그다음에는 i, d.

d는 마지막 글자이므로 초록색으로 표기하겠다. C언어에서는 불리언 연산식으로 여기에 이름 하나가 끝난다는 것을 표시할 수 있다.
이제 이름의 각 글자에 대해 하나의 노드 혹은 배열을 저장하며 Hagrid의 이름을 묵시적으로 저장했다. 그러나 여기에 Hagrid의 접두사나 같은 접두사를 가진 다른 이름들이 저장되어 있을 수 있기 때문에 어느정도 효율성이 있다고 볼 수 있다.
예를 들어 이 자료 구조에 Harry를 넣고 싶다고 하자. H a r r y이므로 이에 해당하는 노드가 생성된다.

이어서 Hermionie를 넣고 싶으면 이 트리에 아래와 같이 노드를 추가하게 된다.

그러나 몇 노드들은 나눠가진다. 맨 위에서 시작해서 H를 바라보면, Hagrid, Harry, Hermionie 모두가 최소 하나의 노드를 나눠 가진다는 것을 볼 수 있다.
이제 이것이 멋진 이유는 뭘까? 이 자료 구조에서 n명 사람들이 있으면 누군가를 찾기 위한 탐색 시간은 어떻게 될까? 현재 노드가 많이 존재함에도 불구하고 총 3명만 있기 때문에 n은 3이다.
Harry는 H a r r y 이므로 최대 5단계를 거친다. Hagrid는 H a g r i d 최대 6단계, H e r m i o n i e는 최대 8단계를 거쳐야 한다. 이처럼 고정된 값의 단계를 거치게 된다.
고정된 값이 있을 경우 수학적으로 혹은 컴퓨터 공학적으로 '상수'라고 부른다. 즉, 고정된 상한이 있다는 것이다.

그래서 엄밀히 말하면 Harry, Hagrid, Hermionie를 찾기 위해 각각 5, 6, 8단계가 걸리기 때문에 그 시간은 O(1) 상수 시간이 된다. 그래서 이 자료 구조를 탐색할 때 k값이 상수인 O(k)라는 것을 달성할 수 있다. 하지만 상수는 점근적으로 O(1)과 같다.
지금까지 설명한 다른 검색과 정렬 알고리즘들은 자료 구조에 있는 이름들의 개수(n)에 따라 실행 시간이 길어졌었다. 하지만 이 자료 구조는 그렇지 않다.
하지만 이에 대가가 있다. 메모리이다. 한 글자를 저장하기 위해 26배의 메모리를 사용하고 있다. 이름을 많이 삽입할수록 몇 노드들은 나눠 사용하지만, 이 자료 구조는 매우 넓고 밀도가 높다. 이론적으로 상수 시간의 실행 시간을 제공하기 위해 아주 많은 양의 메모리를 사용한다.
앞으로 남은 수업에서 하나의 자원을 얻기 위해 다른 자원을 포기하는 이런 균형을 자주 보게 될 것이다.
생각해보기
트라이가 해시 테이블에 비해 가지는 장점과 단점은 무엇일까요?
자료의 개수가 많아질수록 실행 시간이 많이 걸리는 O(n)인데에 비해, 트라이는 자료의 개수에 상관없이 실행 시간이 일정한 O(1)이므로 비교적으로 실행 시간이 매우 빠르다.
하지만 공간복잡도가 높으므로 해시 테이블에 비해 몇 배로 메모리가 많이 소모되는 단점을 가지고 있다.
9. 스택, 큐, 딕셔너리
들어가기 전에
이번 강의에서는 간단하지만 많이 쓰이는 데이터 구조 세 가지를 더 살펴보겠습니다. 이들은 사실 우리가 이미 여태까지 강의에서 은연중에 다뤘던 구조들이기도 합니다. 메모리의 구조에서 잠깐 살펴봤던 ‘스택’과 ‘큐’, 그리고 해시 테이블로 구현할 수 있는 ‘딕셔너리’에 대해 알아보겠습니다.
학습 목표
스택, 큐, 딕셔너리의 원리와 구조를 설명할 수 있습니다.
핵심 단어
- 스택
- 큐
- 딕셔너리
지금까지 배열, 연결 리스트, 트리, 트라이, 해시 테이블을 배웠다. 이러한 것들을 이용해 추상 자료형이라는 것을 구현할 수 있고, 다른 문제를 해결하는 데에도 사용할 수 있다.
큐
그 중 하나가 바로 "큐"이다. 현실에서 큐라고 하면 가장 간단한 예시는 대기 줄이다.
컴퓨터 공학에서의 큐도 기술적인 정의를 가지고 있다. FIFO, 즉 선입 선출의 특징을 가진 자료 구조이다. 정의에 따르면 큐는 사람들이 줄을 선 것이다. 내가 이 줄의 제일 처음에 서 있다면 제일 먼저 음식을 받고 그 다음은 내 뒷사람이 받는 식이다. 늦게 온 사람이 먼저 음식을 받는다면 기분이 무척 나쁠 것이다. 이것은 반대의 자료 구조가 된다. LIFO라 한다. 후입 선출이라 한다. 현실에서는 매우 불공평한 상황이다.
이러한 주문을 받는 시스템 소프트웨어가 있다면 "큐"와 같은 방식으로 보내게 된다. 캠퍼스에서 프린터를 할 때에도 먼저 요청을 보낸 순서대로 프린터를 하기 위해 큐의 방식을 사용한다.
실생활에서는 사용하지 않지만 큐에는 두 가지 기본 연산이 있다. enqueue와 dequeue이다. enqueue는 줄에 들어가서 서는 것이고, dequeue는 줄을 빠져나오는 것이다.
스택
LIFO의 구조인, 큐와 정반대인 구조이다. 식당에 가장 맨 위에 올려진 쟁반을 가장 먼저 가져가는 것을 생각하면 된다. 또한 지메일의 받은 메일함을 생각하면 된다. 항상 최신 메일을 볼 수 있는 기능이라 아주 좋다. 하지만 단점으로는 여러분 친구가 한 시간 전에 메일을 보내면 그 메일이 2페이지 너머 아래로 넘어갈 수 있다는 것이다.
여기에도 트레이드 오프가 있다. 스택을 이용하면 쟁반을 빨리 가져올 수 있고 최신 메일을 볼 수 있는 좋은 기능이 있으나, 메일이 금방 다음 페이지로 넘어가서 이 스택이 다 사라지기 전까지 그 메일을 보지 못할 수도 있다.
다양한 맥락에서 나쁜 속성일 수도 있지만 항상 그런 것은 아니다. 여기서는 큐의 enqueue와 dequeue를 push와 pop이라고 부른다. 스택에 어떤 요소를 밀어 넣고 가장 위의 요소를 뺀다는 의미의 이름이다.
딕셔너리
파이썬을 공부할 때 이것을 다시 본다. 딕셔너리는 해시 테이블이라고 생각할 수 있는 개념이다. 해시테이블을 구현하기 위해 여기서는 바구니를 사용했고 코드에서는 배열과 연결 리스트로 만들었다. 일반적으로 컴퓨터 공학에서의 딕셔너리는 키와 값, 단어와 값, 단어와 페이지 번호 그리고 그 외의 다양한 쌍으로 이루어진 자료 구조이다.
딕셔너리는 현실에 실제로 존재한다. 하버드 광장 Sweetgreen에서 샐러드를 주문하면 해시 테이블과 같은 시스템이 작동한다. 주문자가 David면 D, Brian이면 B아래에 샐러드를 올려둔다. 가게에 들어가서 O(n)만큼 샐러드를 뒤져볼 필요가 없다는 것이다. 바로 B나 D에 가서 자기 샐러드를 가져오면 된다. 하지만 극단적인 상황에서 Harry, Hermione, Hagrid가 모두 동시에 샐러드를 주문하면 H에는 큰 스택이 생긴다. 따라서 엄밀히 말하면 O(n)이 된다. 하지만 이름이 고르게 분포되어 있다면 굉장히 좋은 방식이다.
마지막으로 큐와 스택에 관련된 다음 영상을 보고 강의를 마친다.
'Education' 카테고리의 다른 글
| [부스트 코딩 뉴비 챌린지 2020] week6_샘플미션 : 2개의 연결 리스트 합치기 (0) | 2020.08.14 |
|---|---|
| [부스트 코딩 뉴비 챌린지 2020] week5_LIVE 강의 (0) | 2020.08.14 |
| [부스트 코딩 뉴비 챌린지 2020] week5_미션02 (0) | 2020.08.11 |
| [부스트 코딩 뉴비 챌린지 2020] week5_미션03 (0) | 2020.08.07 |
| [부스트 코딩 뉴비 챌린지 2020] week5_미션01 (0) | 2020.08.07 |
