학습 리스트
- 작업 환경
- Juptyer 사용법
- 자료형
- 문자열 메소드
- 연산 : 산술, 비교, 논리, 비트
- 함수
- 리스트, 튜플, 딕셔러니, 셋
1. 작업 환경
환경은 구름IDE에서 Jupyter로 한다. 이처럼 구름IDE에 접속해서 하는 방법이 있고, 컴퓨터에 아나콘다 설치 후 Jupyter notebook 실행하여 할 수도 있다.
컨테이너를 만들고 '프로젝트 > 실행(Shift + F5)'을 하면 Jupyter notebook이 실행된다.

그 다음 위 화면의 url을 클릭하면 Jupyter notebook에 들어가게 된다. 여기서 'New > python3' 를 클릭하면
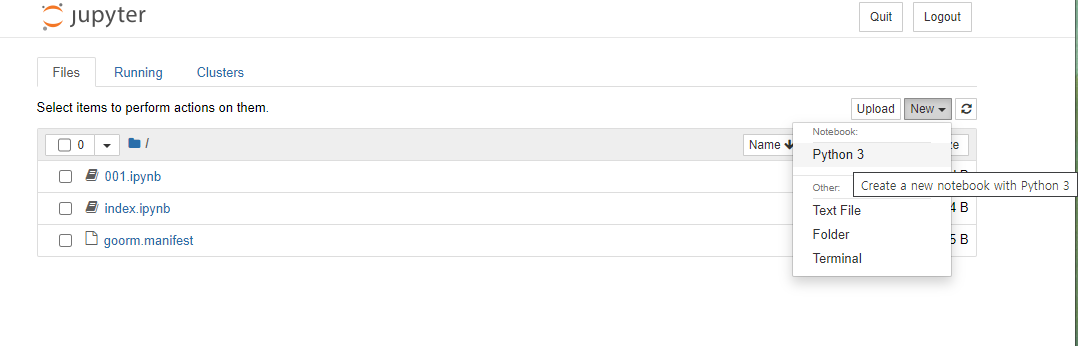
Jupyter notebook 작업 환경이 나온다.
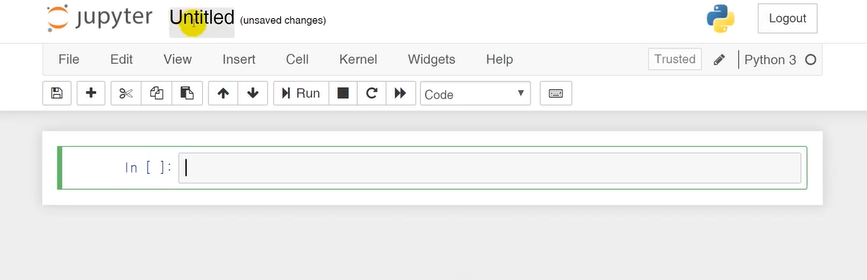
Jupyter 사용법
- ctrl + enter : 실행
- In [n], Out [n] 의 n으로 몇 번째 실행인지 알 수 있다.

- alt + enter : 다른 셀 생성
- 주석 : # / 긴 주석: ''' '''
- ctrl + / : 주석처리
✔︎ 구름IDE 연결할 수 없다는 에러가 뜨는 경우
ctrl + shift + del 인터넷 사용 기록 삭제 후 파일을 누르면 해결된다.
✔︎ tab = space * 4
✔︎ "esc + m" 을 누르면 plantext로 사용 가능하다.

위 값을 입력한 후 alt+enter 를 누르면 아래와 같이 생성된다.

자료형(type)
'문자열+문자열'이 잘 나오는 것을 확인할 수 있다. 이처럼 코드의 세계가 우리의 현실 세계를 바라보고 있다 하여 파이썬 언어를 객체 지향 언어라 한다.

bool
- True or False. (≠ true, false).
- 0 혹은 None(='')이 아닌 값은 모두 True
<예시1>
a = True
b = False
print(type(a))
#<class 'bool'><예시2>
print(bool(' ')) # space가 들어있기 때문에 True
print(bool('')) # 안에 값이 없기 때문
print(bool(0))
print(bool(1))
print(bool(-1))
print(bool(None)) # None: 아무 것도 없음을 나타냄True
False
False
True
True
False
문자열 자료형
작은 따옴표로 감싸준 것

- 인덱스(index): []안에 있는 숫자
- 인덱싱(indexing): 문자열 내 특정한 값을 뽑아냄
- 슬라이싱(slicing): 무언가를 잘라낸다'는 의미
- s[start(a) : stop(b) : step(c)]: c만큼 건너뛰어서 a<= n <b 만큼 출력 (-n: 뒤에서 n 번째. 역순)
문자열 메소드들
In :
s = 'paullab !CEO LeeHoJun'
print(type(s))
print(dir(s))Out :
<class 'str'>
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
_언더바가 없는 메소드들은 모두 문자열을 사용하기 편하도록 만들어진 메소드들이다.
upper(문자열), low(문자열)
- upper(): 모두 대문자로 변경
- low() : 모두 소문자로 변경
s = 'paullab !CEO LeeHoJun'
print(s.upper()) # PAULLAB !CEO LEEHOJUN
print(s.lower()) # paullab !ceo leehojun
문자열.count('문자')
문자열 중 문자의 개수를 출력
s = 'paullab !CEO LeeHoJun'
s.count('l') # 2
strip(문자열), lstrip(문자열), rstrip(문자열)
양쪽 공백을 없애줌. lstrip은 왼쪽만, rstrip은 오른쪽만의 공백을 없애준다.
ss = ' hello world '
print(ss.strip()) #hello world
print(ss.rstrip()) # hello world
print(ss.lstrip()) #hello world
split(문자열)
괄호 속 문자열 별로 쪼개준다.
s = 'paullab !CEO LeeHoJun'
print(s.split(' ')) #['paullab', '!CEO', 'LeeHoJun']
print(s.split('!')) #['paullab ', 'CEO LeeHoJun']
'문자'.join(문자열)
s = 'paullab !CEO LeeHoJun'
a = s.split(' ')
print(a)
print('!'.join(a)) #paullab!!CEO!LeeHoJun
문자열.format()
print('제 이름은 {}입니다. 제 나이는 {}입니다.'.format('이호준',33))
# 제 이름은 이호준입니다. 제 나이는 33입니다.위처럼 {}안으로 format()메소드 속의 값들이 매칭이 된다. 아래와 같이 숫자를 넣을 수도 있다.
print('제 이름은 {0}입니다. 제 나이는 {0}입니다.'.format('이호준',33))
# 제 이름은 이호준입니다. 제 나이는 이호준입니다.
print('제 이름은 {1}입니다. 제 나이는 {1}입니다.'.format('이호준',33))
# 제 이름은 33입니다. 제 나이는 33입니다.단, format()메소드 속 각 값들은 0부터 시작되므로 주의해야 한다.
print 옵션들
,로 연결할 수 있다.
a = 2019
b = 9
c = 24
print(a, b, c) #2019 9 24- end 옵션: 원래 기본으로 print를 하게 되면 끝에 enter가 되는데 원하는 값을 끝에 넣을 수 있다.
a = 2019
b = 9
c = 24
# 2019/9/24
print(a, b, c, end=' ')
print(a, b, c)
#2019 9 24 2019 9 24- sep 옵션: 각각의 요소들을 원하는 문자로 나눌 수 있다.
a = 2019
b = 9
c = 24
print(a, b, c, sep='/')
#2019/9/24
형변환
str(), int(), ...
a = 10
b = '10'
print(a + int(b)) #형변환
print(str(a) + b) #형변환
#20
#1010
연산
산술연산
#산술연산
a = 3
b = 10
print(a + b)
print(a - b)
print(b / a) #float
print(b // a) #int
print(b * a) #float
print(b ** a) #int
print(b % a) #나머지 (0이면 b는 a의 배수)13
-7
3.3333333333333335
3
30
1000
1
비교연산
a = 10
b = 3
print(a >= b)
print(a > b)
print(a <= b)
print(a < b)
print(a == b)
print(a != b)True
True
False
False
False
True
논리연산
a = True # 1
b = False # 0
print(a and b) # *
print(a or b) # +
print(not b) # 반대False
True
True
할당연산
a = 10
a = a + 10
a += 10
print(a) //30
비트연산
a = 40
b = 14
print(a & b)
# 비트연산자들: &, |, ~
print(bin(a))
print(bin(b))8
0b101000
0b1110
101000 (40)
001110 (14)
--------- and연산
001000 (8)
print(bin(a)[2:].zfill(6))
print(bin(b)[2:].zfill(6))101000
001110
: [2:] - 앞의 0b없애기
문자열.zfill(숫자) - 자리수 맞추기
연산자 우선순위
헷갈리면 그냥 괄호로 묶어!
함수
- def f(a, b) : a, b는 파라미터(parameter), 혹은 인자.
- f(x, y) : x, y는 아규먼트(argument).
<예제1>
def f(x, y):
z = x + y
return z
print(f(3, 5)) # 8<예제2>
def ff():
print('1')
print('2')
print('3')
print('4')
ff()4
1
2
3
<예제3> tab (=space * 4)를 한 공백까지가 함수의 범위이므로 다음과 같이 출력된다.
def ff():
print('1')
print('2')
print('3')
print(4)
ff()3
4
1
2
<예제4>
def ff():
print('1')
print('2')
print(ff())1
2
None
왜냐하면 함수의 return 값에는 항상 "None"이 생략되어 있기 때문이다. 즉, 아래를 참고.
def ff():
print('1')
print('2')
return None
<예제5 : 원의 넓이 구하기>
def circle(r):
width = r*r*3.14
return width
print(circle(10)) # 314.0<예제6>
a = 10
def aplus():
a += 10
return a
print(aplus())

함수 내에는 a라는 변수가 없기 때문에 에러가 발생한다. 변수 a를 변경하고 싶다면 함수에 인자값으로 넣어주어야 한다.
a = 10
def aplus(aa):
aa += 10
return aa
print(aplus(a)) #20혹은 "global a"를 함수 안에 사용한다.
a = 10
def aplus():
global a
a += 10
return a
print(aplus()) #20하지만 global 명령어는 다른 함수에 영향을 끼치므로 주의해서 사용해야 한다.
리스트, 튜플, 딕셔러니, 셋
1. 리스트 (list)
- []로 묶음
- 변경이 가능한 자료형
- 순서가 있는 자료형 (슬라이싱 가능)
<예시>
l = [100, 200, 300, 400]
print(l)
print(type(l)) #[100, 200, 300, 400]
print(l[1]) #200 (순서가 있다)
l[1] = 1000
print(l) #[100, 1000, 300, 400] (변경 가능하다)- 리스트의 메소드들
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
- append(값): 리스트의 맨 뒤에 하나의 값을 추가한다
l = [100, 200, 300, 400]
l.append(300)
print(l) #[100, 200, 300, 400, 300]- clear(): 리스트 값을 모두 비운다
l = [100, 200, 300, 400]
l.clear()
print(l) #[]- copy(): 리스트를 복사한다
- count(값): 리스트 속 값의 개수를 센다
l = [100, 200, 300, 400]
print(l.count(300)) #1- extend(값1, 값2, 값3): 리스트 맨 뒤에 여러 개의 값을 추가한다 (append와의 차이점)
l = [100, 200, 300, 400]
l.extend([100, 200, 300]) #여러개의 값을 추가(확장)
print(l) # [100, 200, 300, 400, 100, 200, 300]- index(값): 리스트 속에 있는 값의 위치(인덱스) 반환
l = [100, 200, 300, 400, 100, 200, 300]
print(l.index(400)) #해당 값의 위치(인덱스) 반환
print(l.index(100)) #값이 리스트에 여러개 있는 경우, 제일 앞에 있는 값의 위치를 반환
#3
#0- insert(인덱스, 값): 원하는 위치에 값을 추가함. 이전 값을 삭제하지 않고 사이에 낑겨서 추가된다.
l = [100, 200, 300, 400]
l.insert(3, 1000)
print(l) #[100, 200, 300, 1000, 400]- pop(값): 원하는 인덱스의 값을 삭제함
l = [100, 200, 300, 400, 100, 200, 300]
l.pop() #마지막에 있는 값이 삭제됨
print(l)
l.pop(3) #값을 넣으면 인덱스 3번째 값을 삭제함
print(l)
# [100, 200, 300, 400, 100, 200, 300]
# [100, 200, 300, 100, 200, 300]- remove(값) : 첫 번째 인덱스에 나오는 원하는 값을 삭제
l = [100, 200, 300, 400, 100, 200, 300]
l.remove(100)
print(l) # [200, 300, 400, 100, 200, 300]- reverse() : 리스트를 거꾸로 뒤집음
l = [100, 200, 300, 400]
l.reverse()
print(l) # [400, 300, 200, 100]
#l[::-1] 과 동일한 기능- sort() : 차례대로 정렬해줌
l = [200, 300, 100, 400]
l.sort()
print(l) #[100, 200, 300, 400]- sorted(), reversed() : 직접적으로 값을 만지지 않고, 리턴값만 만짐
2. 튜플 (tuple)
- ()로 묶음
- 순서가 있는 자료형 (슬라이싱 가능)
- 변경이 불가능한 자료형
<예시>
l = [10, 20]
t = (l, 200, 300, 400)
print(t) #([10, 20], 200, 300, 400)
print(type(t)) #<class 'tuple'>
l[0] = 10000
print(t) #([10000, 20], 200, 300, 400)튜플은 값이 안변한다면서요? 하지만 0번째에 l을 참조하고 있다는 것이지, 변경이 불가능하지만 참조 불가능한다는 말이지 값이 변경 불가능하다는 말은 아니다.
3. 셋 (set)
- {}로 묶음
- 순서가 없는 자료형
- 값의 중복을 허락하지 않는다. ←이 용도로 주로 쓰인다 (ex. 알고리즘, ...)
- 메소드들 :
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__init_subclass__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
<예시>
s = {100, 200, 300, 300, 300}
print(s) #{200, 100, 300}
print(type(s)) #<class 'set'><예시2>
순서가 없으므로 add로 값을 추가해도 순서가 뒤섞여 있다.
s = {100, 200, 300, 300, 300}
s.add(500)
print(s) #{200, 100, 500, 300}<예시3 : 셋은 값의 중복을 없애는 용도로 자주 쓰인다>
s = {100, 200, 300, 300, 300}
print(set('aaaabbbbccccddd')) #{'a', 'd', 'c', 'b'}- 셋1.union(셋2) : 셋1을 셋2에 합친다
s = {100, 200, 300, 300, 300}
ss = {1, 2, 3}
print(s.union(ss)) #{1, 2, 3, 100, 500, 200, 300}
4. 딕셔너리
- {key : value}
- 순서가 없는 자료형
- 키의 중복을 허락하지 않는다.
<예시>
순서가 없으므로 d[1]와 같이 인덱싱 불가하며, 키를 넣으면 value를 출력한다
d = {'one' : 10, 'two' : 20}
print(d['one']) #10- 메소드들:
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
- values(), keys(), items() : 모든 해당 값들을 보여줌. items는 key와 value를 리스트 속에 튜플로 보여준다.
d = {'one' : 10, 'two' : 20}
print(d.values())
print(d.keys())
print(d.items())
#dict_values([10, 20])
#dict_keys(['one', 'two'])
#dict_items([('one', 10), ('two', 20)])<items 사용 예시>
d = {'one' : 10, 'two' : 20}
l = list(d.items())
print(l[0]) #('one', 10)
print(l[0][1]) #10다중 인덱싱을 이용하여 특정 값만 출력할 수도 있다.
- copy() : 복사함
jeju = {'banana':5000, 'orange':2000}
seoul = jeju.copy()
jeju['orange'] = 10000
print(seoul) #{'banana': 5000, 'orange': 2000}
print(jeju) #{'banana': 5000, 'orange': 10000}위 코드에서 seoul=jeju 라고 작성하게 되면, print(seoul)시 print(jeju)와 동일하게 된다.
'Education' 카테고리의 다른 글
| [제주코딩베이스캠프] 웹개발 30분 요약 - 5. 30분 요약시리즈 - HTML (0) | 2020.08.18 |
|---|---|
| [제주코딩베이스캠프] 웹개발 30분 요약 - 4. 30분 요약시리즈 - Python 2부 (0) | 2020.08.18 |
| [부스트 코딩 뉴비 챌린지 2020] week5_Q&A : 메모리 해제와 메모리 할당 (0) | 2020.08.17 |
| [부스트 코딩 뉴비 챌린지 2020] week5_샘플미션 (0) | 2020.08.17 |
| [부스트 코딩 뉴비 챌린지 2020] week5_미션03 (0) | 2020.08.17 |
